Si
Vous pouvez exporter vers [Table export] un CSV ou XSLX en utilisant des tableaux (voir Section 7.12.17, «
Enregistrer en tant que fichier CSV
»), des données de projet ( numéro standard [Standard number], texte standard [Standard text], etc. et des données de tableaux )
vous pouvez les importer à nouveau via Table Import [Table import]
vers [Table export] un CSV ou XSLX en utilisant des tableaux (voir Section 7.12.17, «
Enregistrer en tant que fichier CSV
»), des données de projet ( numéro standard [Standard number], texte standard [Standard text], etc. et des données de tableaux )
vous pouvez les importer à nouveau via Table Import [Table import]
 avec des données enrichies.
avec des données enrichies.
La procédure est expliquée à l'aide d'un exemple.
Le
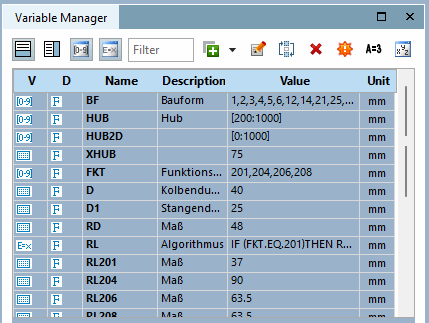
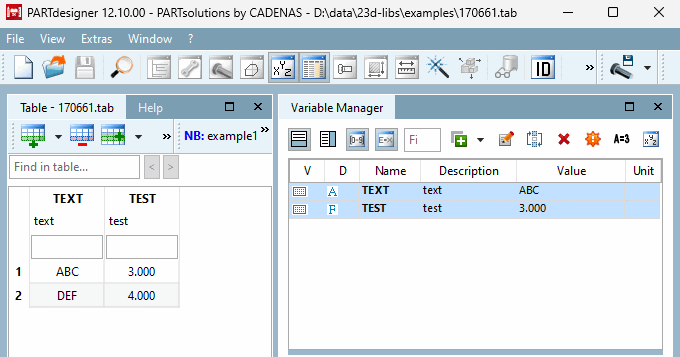
La table ne contient que les variables TEST et TEXT.
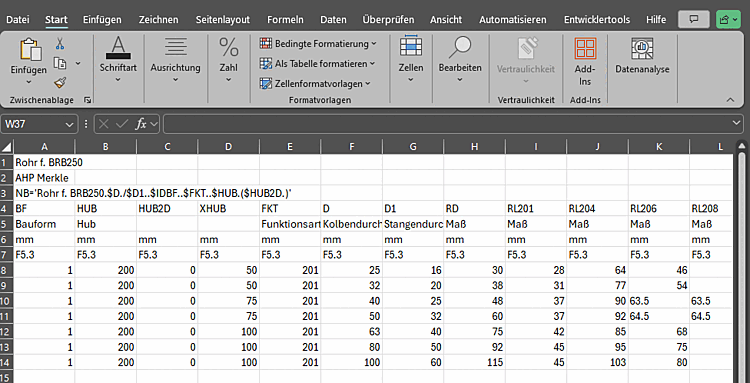
Les données du fichier CSV/XLSX suivant doivent être lues
devenir. TEST et TEXT avec
Les mêmes valeurs que dans la situation initiale sont déjà incluses. Le
D’autres données doivent maintenant être ajoutées à la table.
devenir.
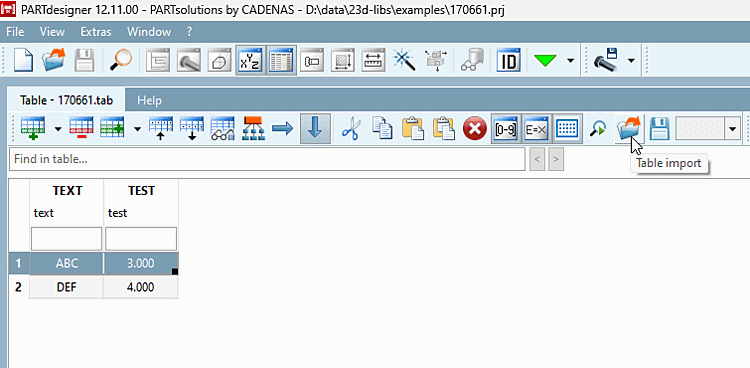
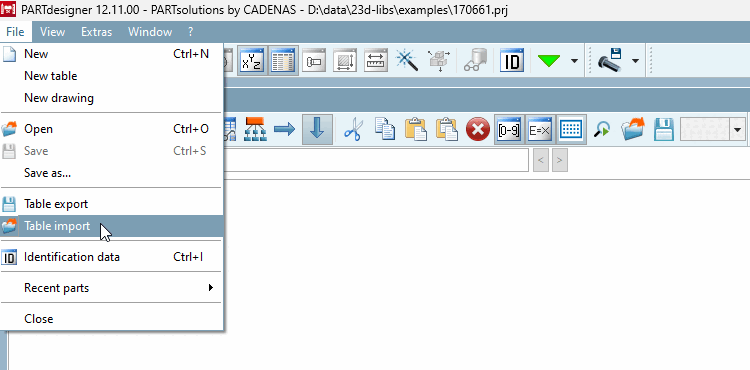
Au-dessus de la table ou dans le Fichier [File], la commande
 tables
Importation [Table import].
tables
Importation [Table import].
Dans la boîte de dialogue, sélectionnez le format de fichier souhaité ainsi que d'autres paramètres.
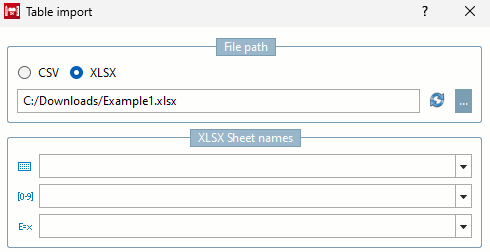
Lors du choix de XLSX la zone de sélection supplémentaire Noms des feuilles XLSX s’affiche [XLSX Sheet names]. Vous y trouverez un Sélectionnez une feuille spécifique à importer. Si vous entrer le chemin manuellement, vous devez utiliser le
 noms des feuilles Nouveau
Chargez [Refresh sheet names] ensuite la sélection.
noms des feuilles Nouveau
Chargez [Refresh sheet names] ensuite la sélection.
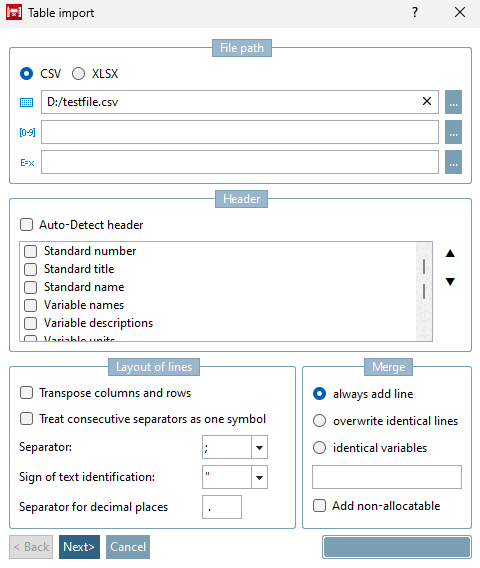
Avant de pouvoir importer un fichier CSV/XLSX dans le tableau, il faut procéder à quelques réglages.
Dans le champ En-tête [Header], vous déterminez quels éléments du fichier CSV/XLSX doivent être repris dans les en-têtes de colonne du tableau. Cochez les options souhaitées.
Si l'ordre n'est pas correct, sélectionnez l'option correspondante et déterminez la position souhaitée à l'aide des touches fléchées. L'option supérieure devient le titre proprement dit de la colonne.
Si la case à cocher Détecter automatiquement les [Auto-Detect header] en-têtes est activée, le système tente de détecter automatiquement les en-têtes à importer à l'ouverture de la boîte de dialogue (ou lorsque la case à cocher est activée). Cela comprend aussi bien les en-têtes à importer que leur ordre. Si toutes les lignes de la première colonne peuvent être identifiées, la case à cocher est activée et la configuration manuelle des en-têtes est désactivée. Dans le cas contraire, elle reste désactivée et l'utilisateur doit indiquer l'en-tête manuellement. Des messages d'avertissement correspondants apparaîtront de la part du système.
Structure des lignes [Layout of lines]
Transposer les colonnes et les lignes [Transpose columns and rows]:
Non transposé signifie une variable par colonne. Transposé signifie que les colonnes et les lignes sont inversées et qu'il y a une variable par ligne. Ceci est pris en charge pour les fichiers CSV et XLSX.
Les exportations non transposées peuvent également être importées dans des versions plus anciennes de PARTdesigner. Si le tableau exporté contient des en-têtes, la détection automatique des en-têtes détecte également si l'entrée est transposée. Cela permet désormais des exportations & importations très importantes, car les restrictions XLSX sont plus importantes pour les lignes que pour les colonnes. Les limites officielles sont de 1.048.576 lignes et 16.384 colonnes.
Traiter les séparateurs successifs comme un seul caractère [Treat consecutive separators as one symbol]:
Dans certains fichiers CSV/XLSX, plusieurs espaces successifs séparent les différentes informations. Pour que PARTdesigner n'interprète pas chaque espace comme un séparateur séparé dans de telles constellations, vous pouvez faire regrouper des groupes d'espaces avec cette option.
Caractère de séparation [Separator]: Caractère permettant de séparer les différents champs.
Identificateur de texte [Sign of text identification]: caractère permettant de délimiter des chaînes de caractères (en règle générale, double guillemet "").
Exemple avec la virgule comme séparateur [Separator] et les guillemets comme identificateur de texte [Sign of text identification]
Séparateur pour les chiffres après la virgule [Separator for decimal places]:
Les décimales peuvent être séparées soit par une virgule, soit par un point.
Unité pour les variables de nombre [Unit for numeric variables]:
Si aucune unité n'a encore été définie dans le fichier CSV/XLSX, vous pouvez le faire dans le champ Unité pour les variables de paiement [Unit for numeric variables].
Toujours ajouter des lignes [always add line]: Toutes les lignes du CSV/XLSX sont toujours ajoutées au tableau.
Écraser les lignes identiques [overwrite identical lines]: Si le tableau existant contient la même ligne que le CSV/XLSX, il sera écrasé. Toute autre ligne sera ajoutée au tableau.
Variables correspondantes [identical variables]: Les valeurs des variables qui sont inscrites dans le champ de saisie en dessous sont comparées, c'est-à-dire les valeurs du tableau et du CSV/XLSX. Si une correspondance est trouvée, le tableau est mis à jour avec les valeurs du CSV/XLSX.
Si aucune correspondance n'est trouvée ET que l'option Ajouter non attribué [Add non-allocatable] est activée, la ligne sera ajoutée au tableau.
S'il n'y a pas d'entrées dans le champ de saisie, aucun match ne sera trouvé.
Si l'option Ajouter non affecté [Add non-allocatable] n'est pas activée, aucune ligne ne sera ajoutée, mais les nouvelles variables seront incluses.
Dans cet exemple, l’option Variables correspondantes [identical variables] utilisées Et dans le champ de saisie, les variables déjà existantes
TESTetTEXTsont saisies. Avec cela , aucune nouvelle ligne n’est créée lors de l’importation, mais la fonction avec les données supplémentaires.
→ Un aperçu s'ouvre. Si vous souhaitez encore apporter des modifications, vous accédez à la fenêtre précédente en cliquant sur < . En outre, les champs eux-mêmes sont éditables.
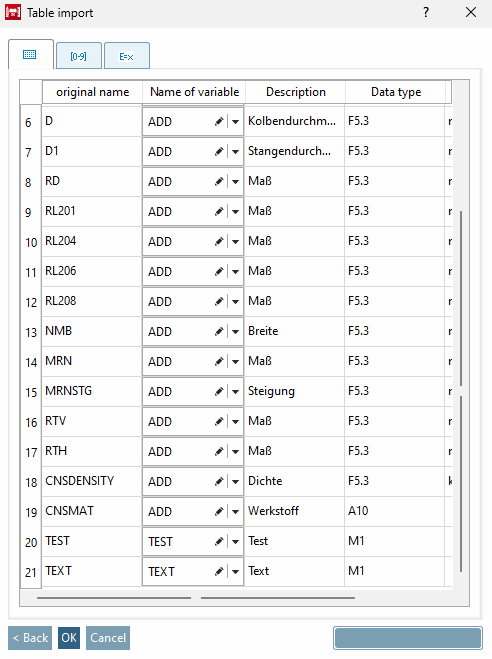
Nom original [Original name]: les variables du fichier CSV/XLSX sont listées dans la colonne Nom original [Original name].
Nom de la variable [Name of variable]: si, lors de la lecture du fichier CSV/XLSX, des concordances sont trouvées avec le tableau actuel, elles sont immédiatement inscrites dans la colonne Nom de la variable [Name of variable] du tableau d'aperçu.
Si le fichier CSV contient de nouvelles variables qui n'existent pas encore, veuillez effectuer le paramétrage correspondant dans la zone de liste :
Description: correspond à la description de la variable [Variable description] sous En-tête [Header] sur la page précédente
Type de données [Data type]: voir gestionnaire de variables [Variable Manager] → colonne D
Unité [Unit]: correspond à l' unité de la variable [Unit of the variable] sous En-tête [Header] sur la page précédente
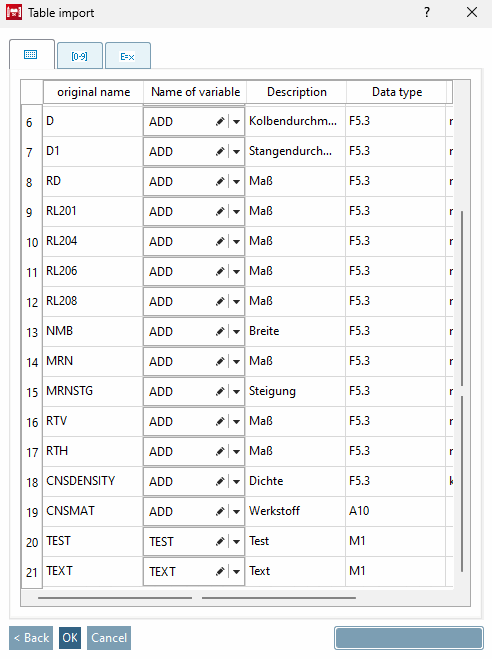
Si l'aperçu montre des affectations de colonnes erronées (cf. Fig. „Aperçu“), vous pouvez corriger l'ordre dans la zone de dialogue En-tête [Header]. Sélectionnez l'option correspondante et déterminez la position souhaitée à l'aide des touches fléchées. (L'option supérieure devient le titre proprement dit de la colonne).
L'illustration suivante montre maintenant l'affectation correcte des colonnes.
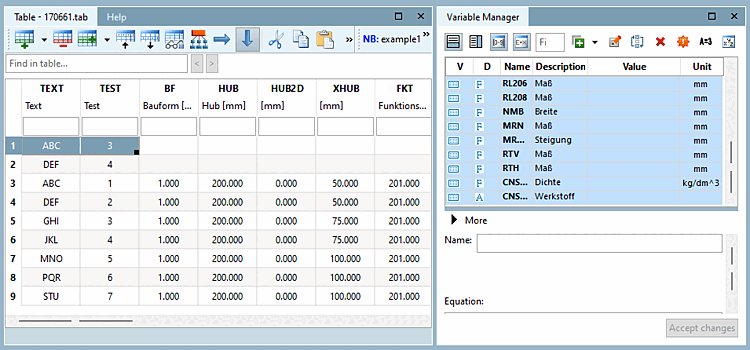
→ Les données sont lues dans le tableau.
Enregistrez le fichier de tableau que vous venez de créer.
![[Remarque]](https://webapi.partcommunity.com/service/help/latest/pages/fr/partsolutions_user/doc/images/note.png)
Remarque Lors du premier enregistrementd'un tableau, des données d'identification [Identification data] doivent être fournies (voir Section 7.18.9, « Données d'identification »).
![[Astuce]](https://webapi.partcommunity.com/service/help/latest/pages/fr/partsolutions_user/doc/images/tip.png)
![Exemple avec la virgule comme séparateur [Separator] et les guillemets comme identificateur de texte [Sign of text identification]](https://webapi.partcommunity.com/service/help/latest/pages/fr/partsolutions_user/doc/resources/img/img_b46055c7aa8b49c7983f9ce10a3f9c3b.png)