
L'analyse des doublons est un outil central pour le contrôle de la qualité des données - en particulier pour les grandes quantités de données et les catalogues importés. Elle trouve les candidats aux doublons, mais ne les élimine pas automatiquement, elle constitue la base des processus de nettoyage en aval.
Concrètement, cela signifie pour le déroulement :
L'exemple suivant donne un petit aperçu du fonctionnement.
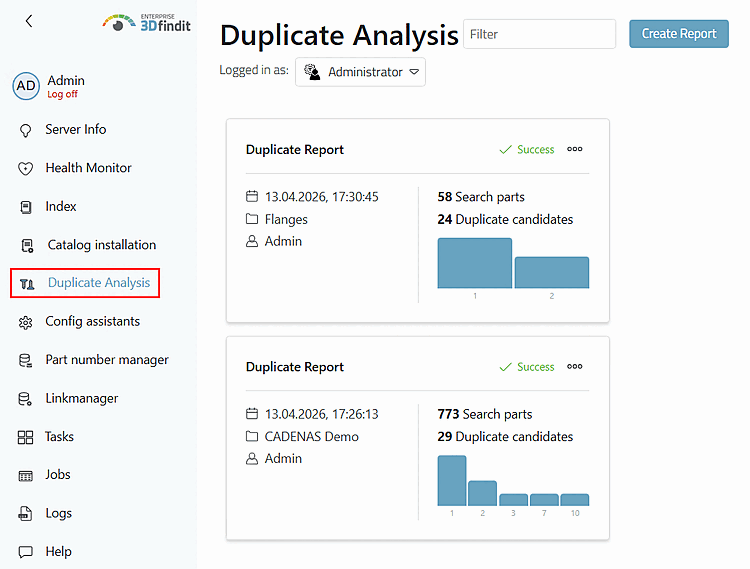
Ouvrez le tableau de bord et sélectionnez l'option de menu Duplicate Analysis.
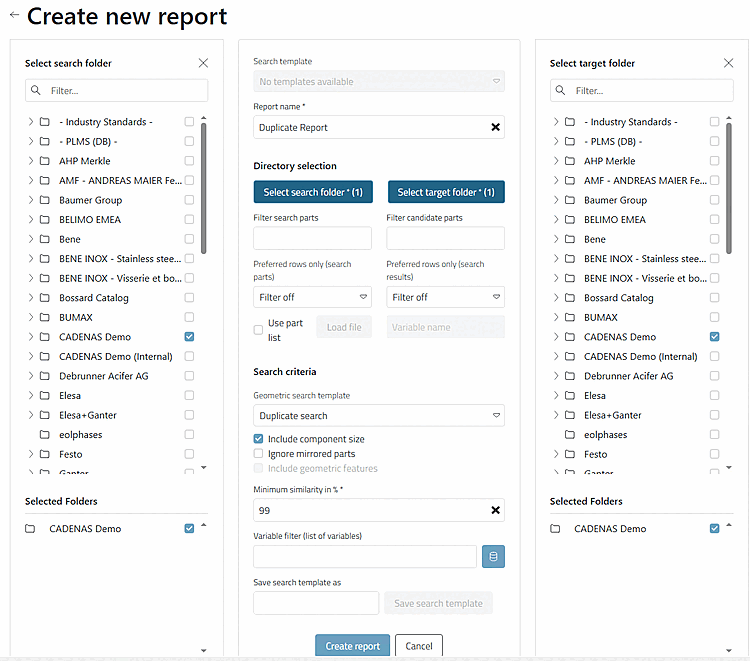
Remplissez les différents points.
Choisissez en particulier le répertoire de recherche et le répertoire cible.
Déterminez la similitude minimale.
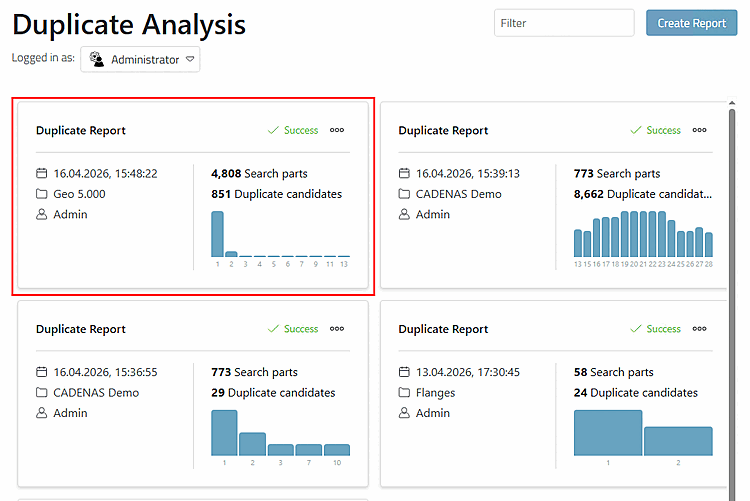
-> La carte du rapport nouvellement créé s'affiche.
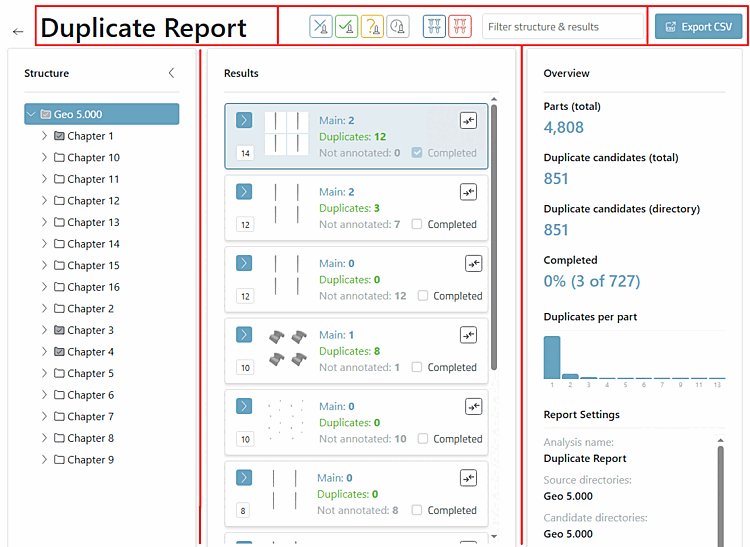
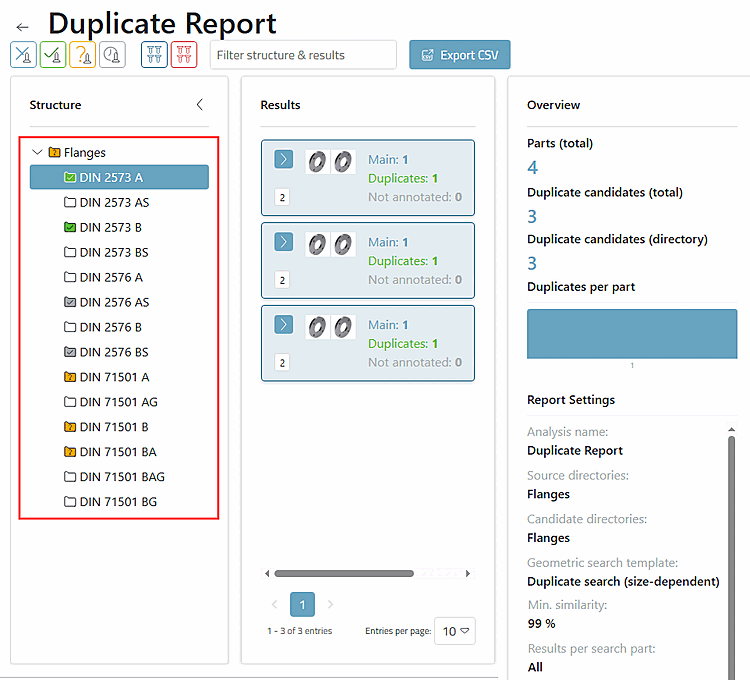
La page du rapport s'articule comme suit :
L'en-tête contient le nom du rapport, une zone de filtrage et un bouton d .
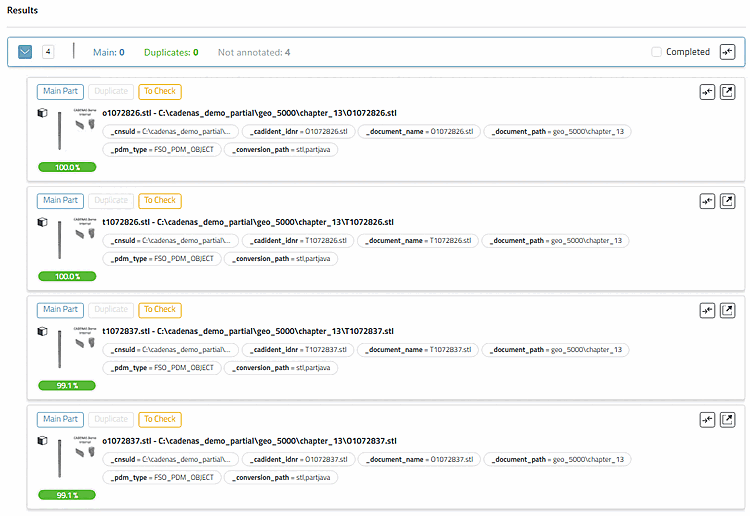
La zone principale est divisée en arborescence [à gauche], résultats [au centre] et une vue d'ensemble [à droite] (sera adaptée en fonction des travaux effectués sur les différents clusters).
Cliquez sur un cluster pour l'ouvrir.
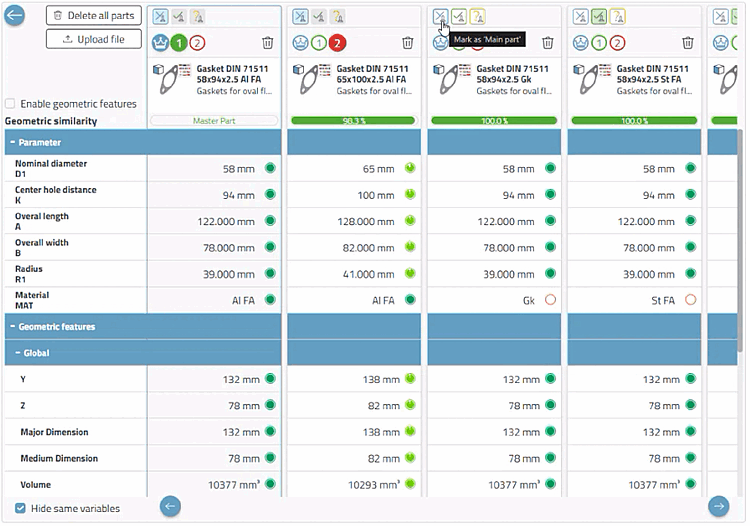
Toutes les parties d'un cluster démarrent en tant que candidats non annotés (Main = 0 et Duplicates = 0). Il n'existe pas encore de Main Part.
Ouvrir un cluster en cliquant dessus. Les sont désactivés tant qu'il n'existe pas de Main Part.
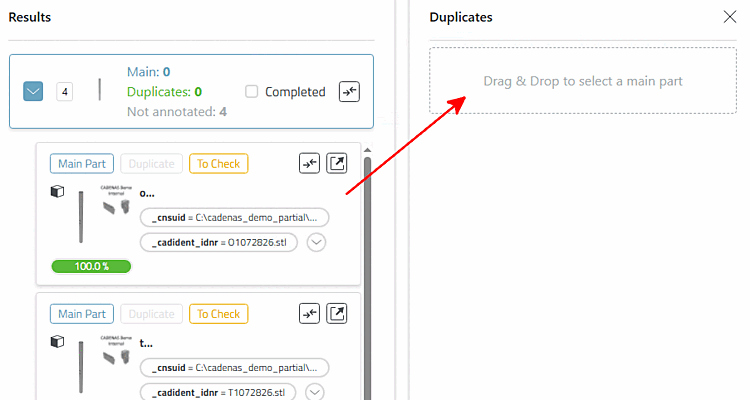
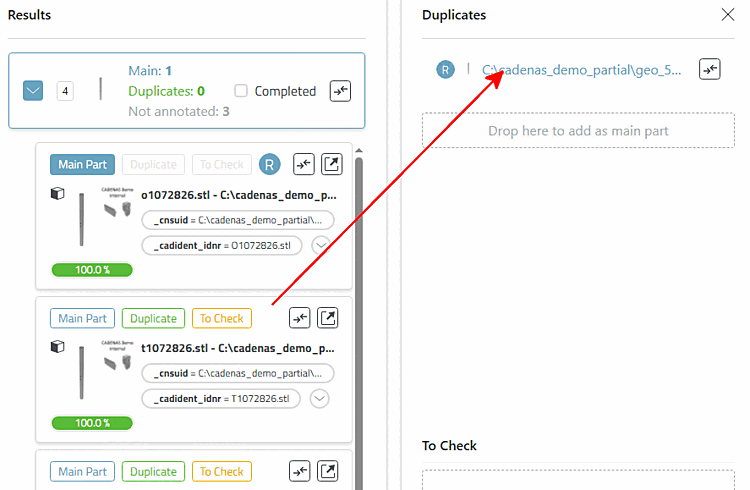
Déterminer une Main Part (doublon candidat → Main Part)
Un candidat peut être annoté en tant que doublet par
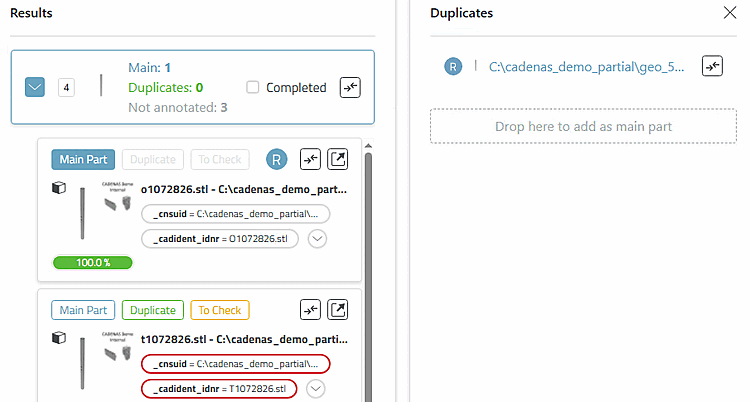
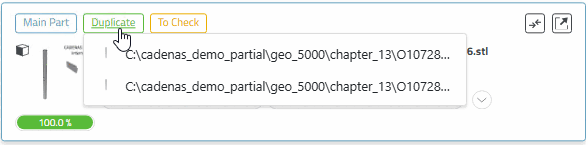
Cliquez sur le bouton "Dupliquer". [Duplicate]
-> Le bouton est rempli avec la couleur de base verte.
ou en glissant-déposant le candidat sur une partie principale existante.
S'il existe plusieurs Main Part, une liste de sélection s'ouvre pour choisir la destination Main Part.
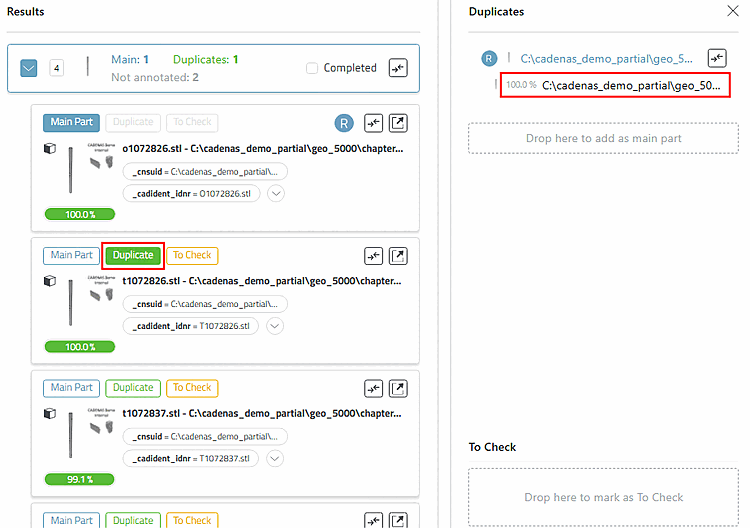
Dans tous les cas, le bouton est maintenant entièrement rempli en vert et le doublon est affiché à droite dans la zone Duplicates sous la Main Part.
Procédez maintenant de la même manière avec tous les autres doublons candidats :
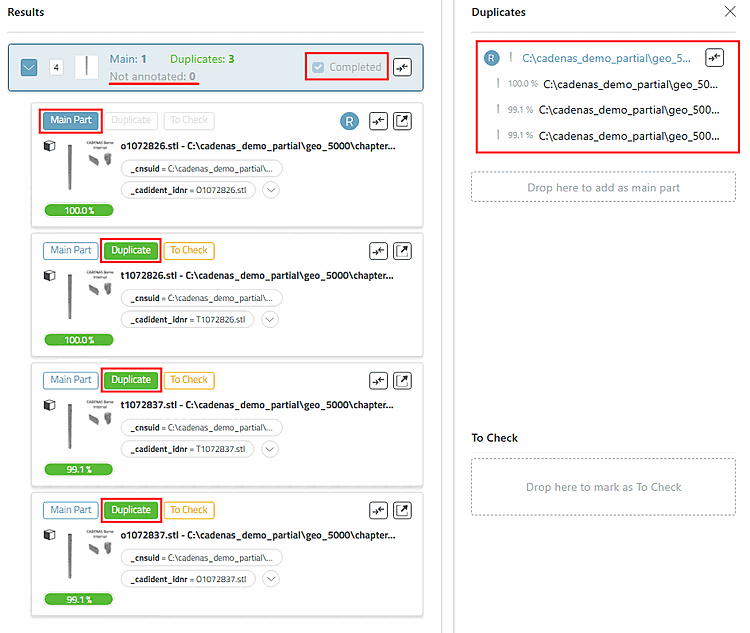
L'objectif est qu'un cluster soit défini comme Completed, c'est-à-dire qu'il ne contienne plus que des Main Parts et des doublons attribués.
Dans l'arborescence à gauche, vous avez à tout moment le contrôle de l'avancement.
Les couleurs dans l'arbre aident à trouver rapidement les clusters ouverts et à rouvrir de manière ciblée les clusters problématiques :
Gris = Ici, au moins un cluster a été achevé, mais d'autres doivent encore être traités.
Jaune = Ici se trouve une partie ToCheck, il faut absolument continuer à compléter ici.
Mais le jaune l'emporte sur le vert, c'est-à-dire que si tous les clusters sont terminés (vert) mais qu'il y a une partie "A vérifier" dans l'un de ces clusters (jaune), le dossier sera marqué en jaune.
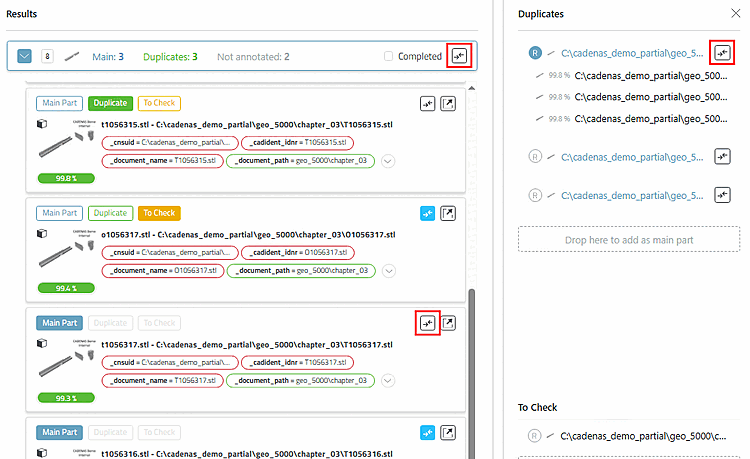
Via Comparaison Button
 peut charger des pièces dans la comparaison à tout moment
.
peut charger des pièces dans la comparaison à tout moment
.Les opérations dans la comparaison et dans l'analyse des doublons sont synchronisées.
Le bouton de comparaison du cluster lui-même (tout en haut) et celui sur la droite (partie racine) remplacent toutes les pièces qui sont jusqu'alors dans la comparaison des pièces.
Les boutons de comparaison dans la liste des pièces (doublons candidats du cluster) ajoutent la pièce en question individuellement, sans supprimer les précédentes.
Les principes de base de la comparaison des pièces en double sont les mêmes que pour le standard ; quelques fonctionnalités ont été ajoutées ici :
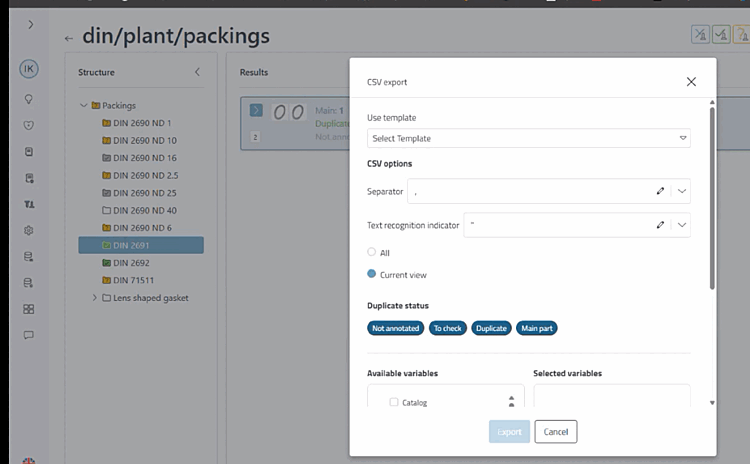
En cliquant sur le bouton , vous pouvez finalement effectuer une exportation pour tous les clusters (option All ) ou seulement pour les états intermédiaires (option Current view ).




Pour plus de détails, voir Section 2.2, « Analyse des doublons » in ENTERPRISE 3Dfindit (Professional) - Administration.