
Die Dublettenanalyse ist ein zentrales Werkzeug zur Datenqualitätskontrolle – insbesondere bei großen Datenmengen und importierten Katalogen. Sie findet Dublettenkandidaten, beseitigt sie aber nicht automatisch, sondern bildet die Grundlage für nachgelagerte Bereinigungsprozesse.
Konkret bedeutet dies für den Ablauf:
Das folgende Beispiel soll einen kleinen Überblick zur Funktionsweise geben.
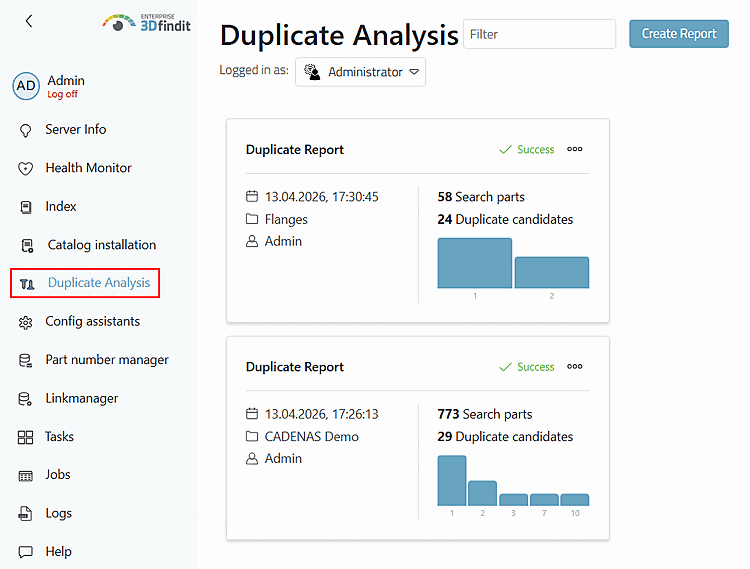
Öffnen Sie das Dashboard und wählen Sie den Menüpunkt Duplicate Analysis.
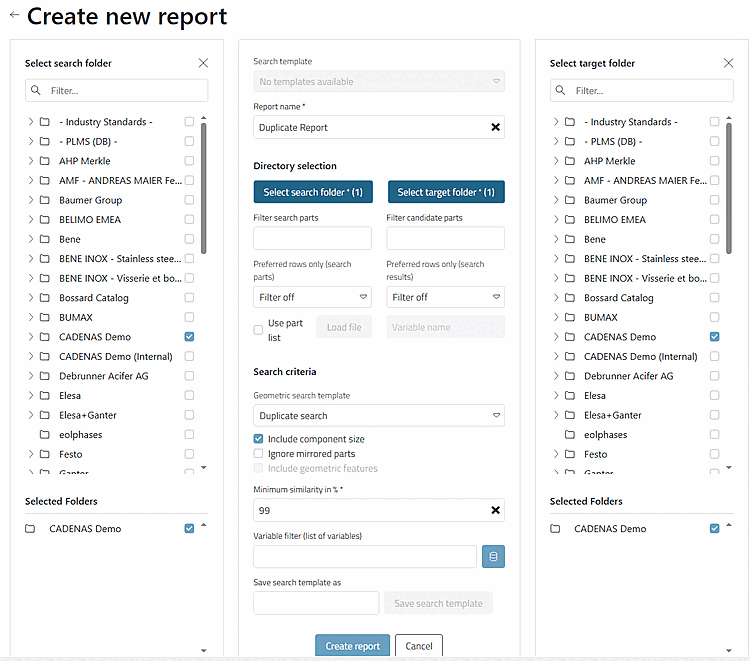
Füllen Sie die einzelnen Punkte aus.
Wählen Sie insbesondere das Such- und das Zielverzeichnis.
Bestimmen Sie die minimale Ähnlichkeit.
Klicken Sie abschließend auf .
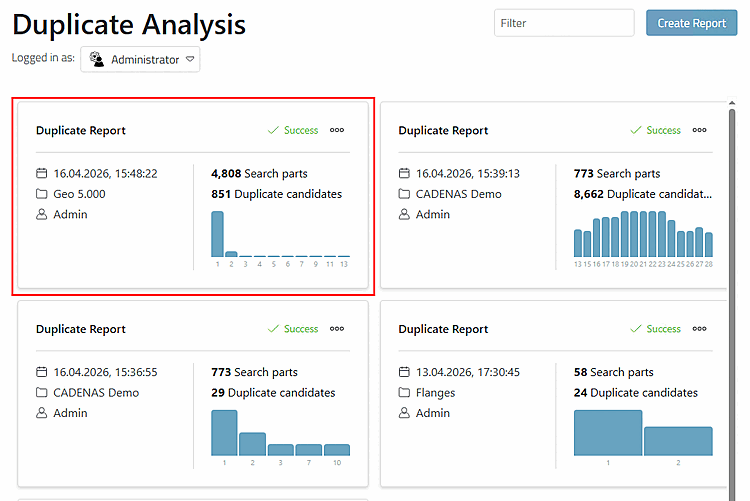
-> Die Karte des neu erstellten Reports wird angezeigt.
Öffnen Sie den Report mit einem Klick.
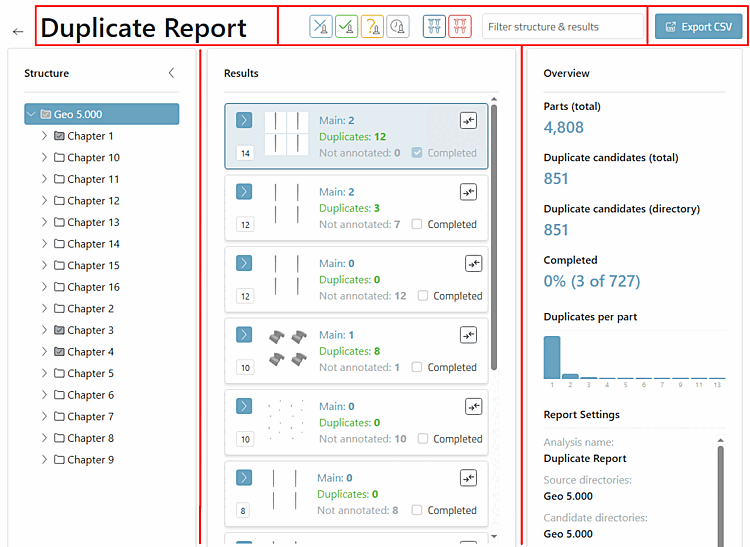
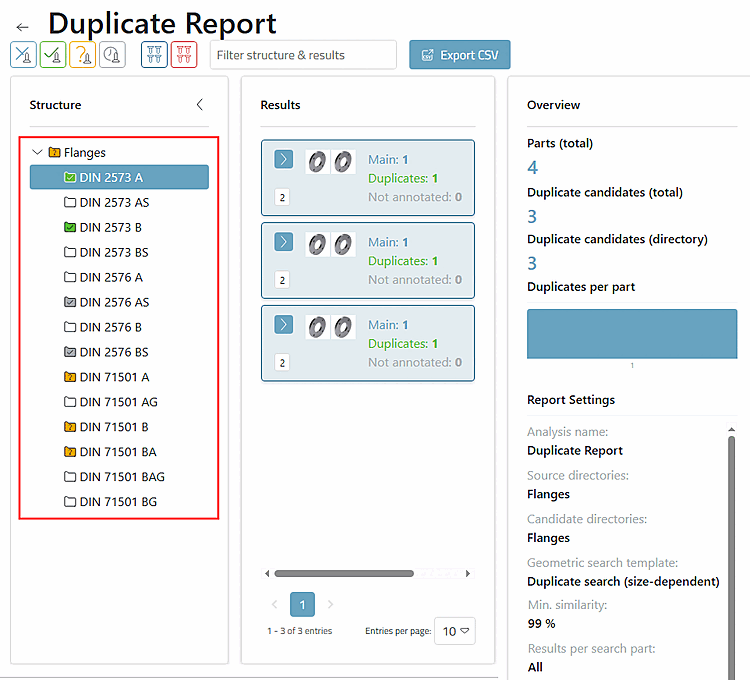
Die Reportseite gliedert sich folgendermaßen:
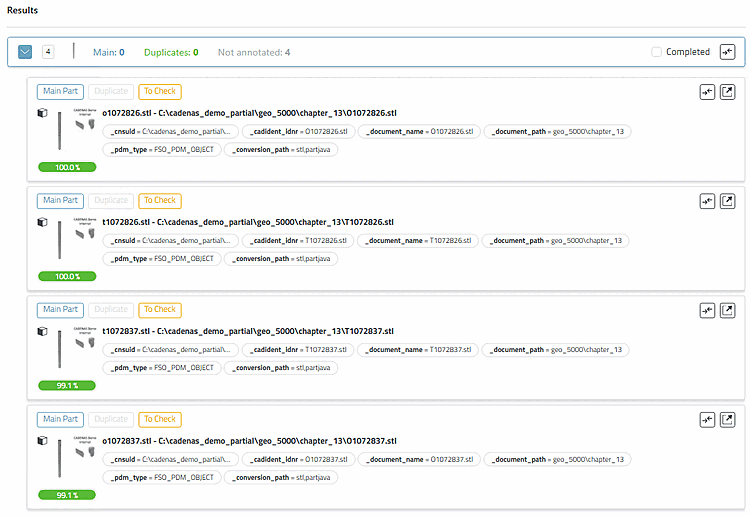
Der Header enthält den Namen des Reports, einen Filterbereich und einen Button.
Der Hauptbereich ist untergliedert in Strukturbaum [links], Ergebnisse [mittig] und einen Überblick [rechts] (wird angepasst entsprechend der Arbeiten an den einzelnen Clustern).
Klicken Sie auf ein Cluster, um es zu öffnen.
Alle Teile eines Clusters starten als nicht annotierte Kandidaten (Main = 0 und Duplicates = 0). Es existiert noch kein Main Part.
Öffnen Sie ein Cluster durch Anklicken. Die -Buttons sind deaktiviert, solange kein Main Part existiert.
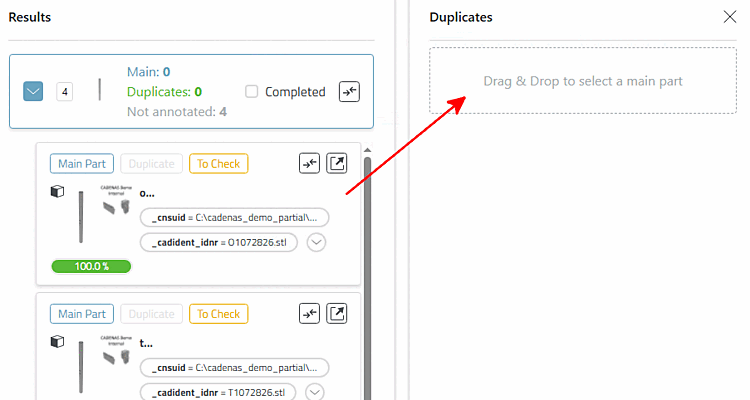
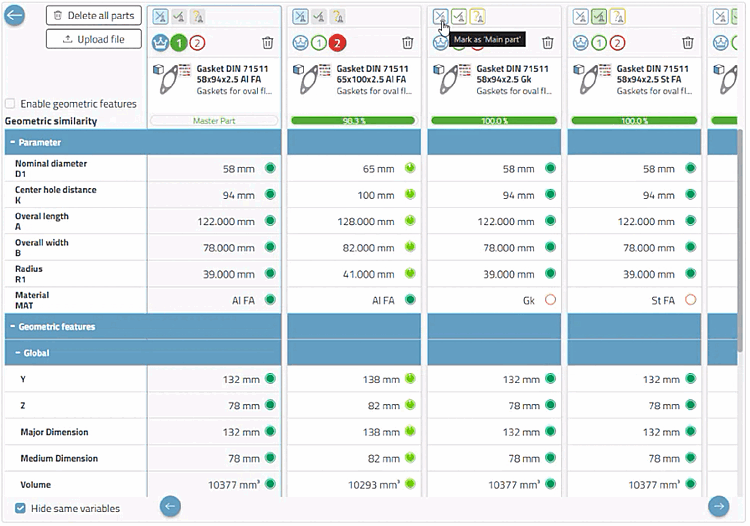
Bestimmen Sie ein Main Part (Dublettenkandidat → Main Part)
Ein Kandidat kann als Dublette annotiert werden durch
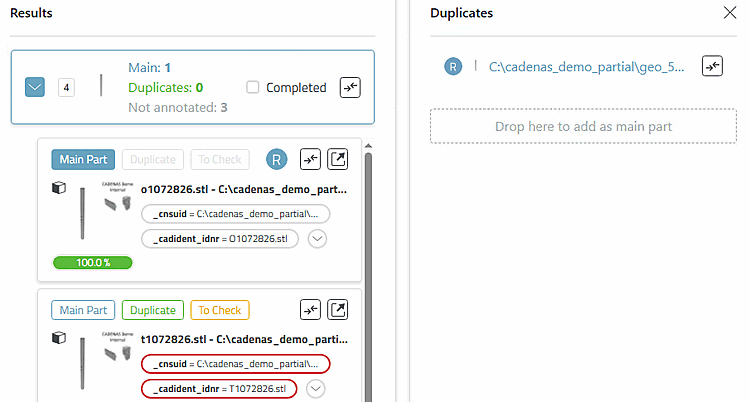
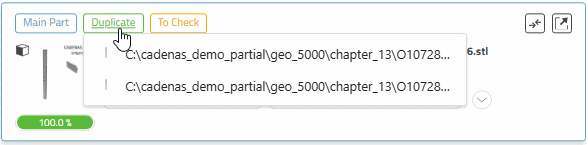
Klick auf den Duplicate-Button
-> Der Button wird mit der grünen Grundfarbe ausgefüllt.
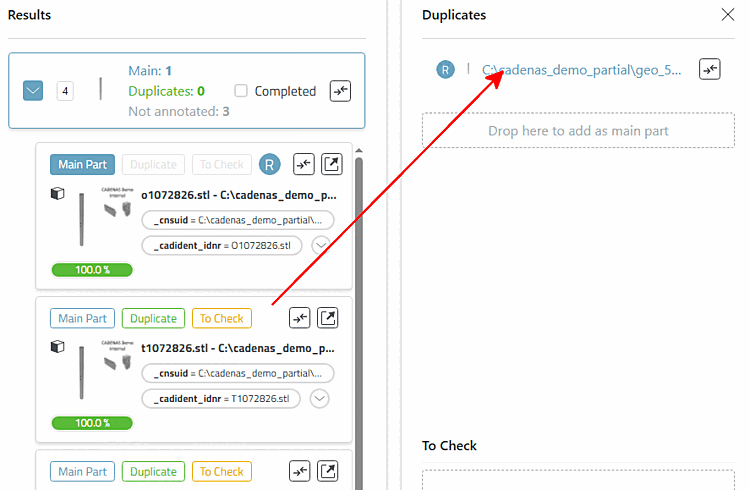
oder indem man den Kandidaten per Drag & Drop auf ein bestehendes Main Part zieht.
Wenn mehrere Main Part existieren, öffnet sich eine Auswahlliste, um das Ziel Main Part zu wählen.
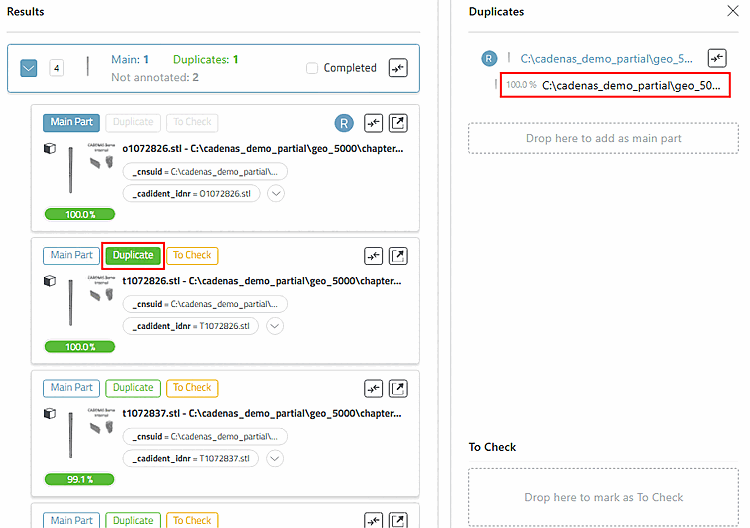
In jedem Fall ist der Button nun in grüner Farbe voll ausgefüllt und die Dublette wird rechts im Bereich Duplicates unter dem Main Part angezeigt.
Verfahren Sie nun auf diese Weise mit allen übrigen Dublettenkandidaten:
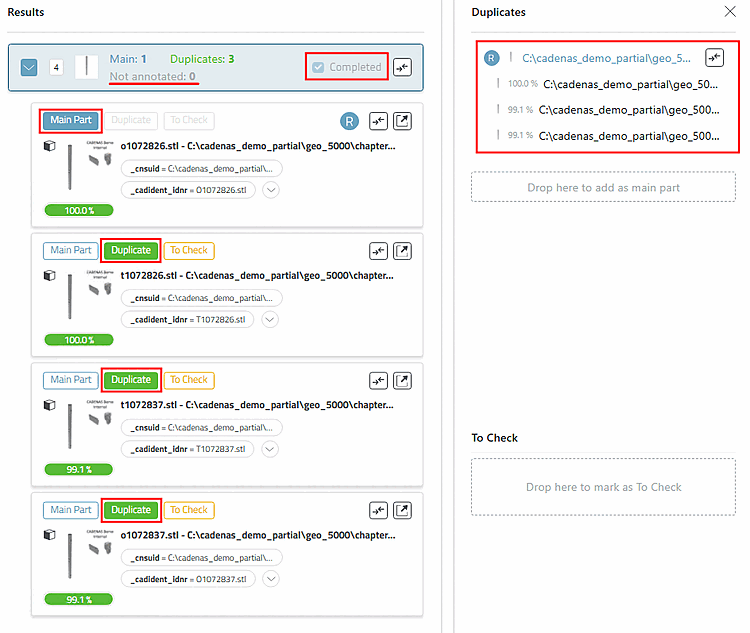
Ziel ist, dass ein Cluster als Completed gesetzt ist, also nur noch Main Parts und zugewiesene Dubletten enthält.
Im Strukturbaum links haben Sie jederzeit die Kontrolle über den Fortschritt.
Die Farben im Baum helfen, offene Cluster schnell zu finden und gezielt problematische Cluster erneut zu öffnen:
Grau = Hier wurde mind. ein Cluster abgeschlossen, aber es müssen noch weitere bearbeitet werden.
Gelb = Hier befindet sich ein ToCheck Teil, hier muss auf jeden Fall weiter vervollständigt werden.
Aber Gelb schlägt Grün, d.h., wenn alle Cluster abgeschlossen sind (Grün), es aber ein "Zu Prüfen" Teil in einem dieser Cluster gibt (Gelb), dann wird der Ordner gelb markiert.
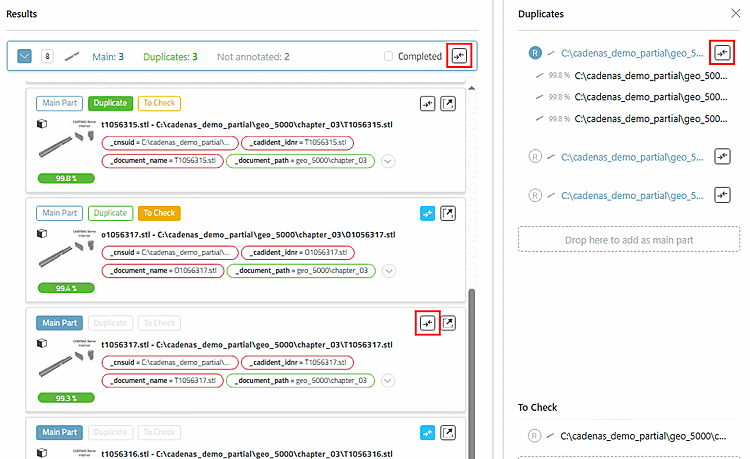
Via Vergleich Button
 können jederzeit Teile in den Vergleich geladen
werden.
können jederzeit Teile in den Vergleich geladen
werden.Operationen im Vergleich und in der Dublettenanalyse laufen synchron.
Der Vergleich-Button des Clusters selbst (ganz oben) und der auf der rechten Seite (Stammteil) ersetzen alle Teile, die bis dahin im Teilevergleich sind.
Die Vergleich-Buttons in der Teileliste (Dublettenkandidaten des Clusters) fügen das jeweilige Teil einzeln hinzu, ohne die vorherigen zu löschen.
Die Grundprinzipien beim Teilevergleich von Dubletten sind dieselben wie beim Standard; ein paar Features sind hier dazugekommen:
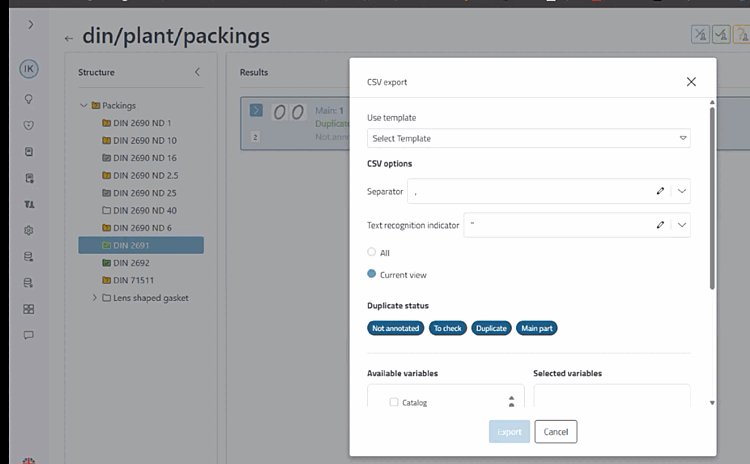
Mit Klick auf den Button können Sie abschließend für alle Cluster (Option All) oder auch nur für Zwischenstände (Option Current view) einen Export durchführen.




Details finden Sie unter Abschnitt 2.2, „ Dublettenanalyse “ in ENTERPRISE 3Dfindit (Professional) - Administration.