1.4.5. Installazione/configurazione di PARTapplicationServer 1.4.5.2. Panoramica dell'installazione multisito
|  |
| Indietro | Avanti |
Il diagramma seguente mostra l'architettura di un'installazione multisito.
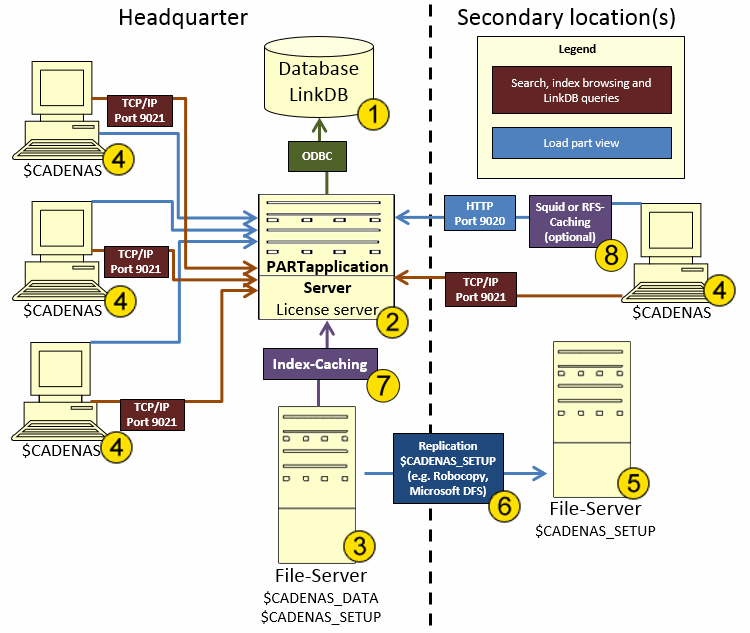
Di seguito troverete spiegazioni e ulteriori link ai singoli componenti e processi del grafico:

|
Il database dei collegamenti 3Dfindit (LinkDB) viene configurato come un nuovo database su un server di database esistente. Non è necessario alcun nuovo software sul server del database. Sezione 5.2, “ Database dei link di installazione ”Informazioni dettagliate sono disponibili all'indirizzo . |

|
Si consiglia di utilizzare un server o una macchina virtuale separata per PARTapplicationServer.
È sufficiente un PARTapplicationServer centrale per tutte le sedi. Tutti i client ottengono i dati dettagliati dei risultati della ricerca da un file server centrale CADENAS_DATA. Su questo server è opportuno installare il servizio licenze di CADENAS. Vedere Capitolo 7, Server licenze in Installazione. |

|
Posizione principale del file server Per i cataloghi CADENAS e la directory di setup è sufficiente una nuova release su un file server esistente. Non è necessario un nuovo software sul file server.
|

|
CADENAS sui client (software e interfacce 3Dfindit) Distribuzione del software / aggiornamenti del software In ambienti di installazione complessi, è consigliabile creare un client di amministrazione e copiarlo utilizzando gli strumenti di distribuzione software standard dell'azienda.Vantaggio: gli aggiornamenti del software possono essere eseguiti con la stessa facilità anche in un secondo momento. |

|
Posizione secondaria del file server(directory di impostazione [CADENAS_SETUP]) |

|
CADENAS_SETUP può essere facilmente replicato (ciclicamente o su richiesta) dal sito principale ai siti secondari (ad esempio con Robocopy, Microsoft DFS o strumenti simili). |

|
Affinché PARTapplicationServer funzioni in modo efficiente, si consiglia di memorizzare nella cache i file di indice CADENAS_DATA. Sezione 1.4.5.8.1.9, “ Cache dei file indice da CADENAS_DATA su PARTapplicationServer ” Sezione 1.4.5.4, “Metodi di caching per l'archiviazione e il lavoro dei dati ”Informazioni dettagliate al riguardo sono disponibili su e . |

|
Caching RFS o SQUID (opzionale) Per ottimizzare il flusso di dati tra client e server, è possibile memorizzare nella cache i dati utilizzati di frequente (in particolare i file di progetto e ZJV). Per gli assiemi di grandi dimensioni (comprese le parti native), le prestazioni possono essere migliorate se necessario. Sezione 1.4.5.8.2.4, “Caching sul lato client o su postazioni secondarie ” Sezione 1.4.5.4, “Metodi di caching per l'archiviazione e il lavoro dei dati ”Vedi e . |
![[Nota]](https://webapi.partcommunity.com/service/help/latest/pages/it/3dfindit/doc/images/note.png)