- 5.8.2.1.20.1.1. Ajouter une variable / Modifier la valeur d'une variable
- 5.8.2.1.20.1.2. Modifier la valeur d'une variable
- 5.8.2.1.20.1.3. Remplacer la valeur d'une variable
- 5.8.2.1.20.1.4. Supprimer les variables
- 5.8.2.1.20.1.5. Renommer une variable
- 5.8.2.1.20.1.6. Ajouter une variable à partir d'un CSV/Reprendre des valeurs à partir d'un CSV
- 5.8.2.1.20.1.7. Possibilités de saisie dans le champ "Nom de la variable
- 5.8.2.1.20.1.8. Utilisation de mots-clés
- 5.8.2.1.20.1.9. Insérer un plan/une esquisse
Les tableaux de caractéristiques matérielles attribués aux différentes parties/projets d'un catalogue peuvent être modifiés par batch (traitement par lots).
Il existe différentes manières d'éditer les variables du tableau. Le choix du mode souhaité se fait dans la zone de liste supérieure :
Selon l'option choisie, les champs de saisie correspondants sont actifs dans les sections Critères de recherche [Search criteria] et Valeurs à définir [Values to set].
![Traiter en mode batch [Edit in batch]](https://webapi.partcommunity.com/service/help/latest/pages/fr/partsolutions_user/doc/resources/img/img_890e4bd9713f44cf926a90f30478da3b.png)
Définissez les paramètres appropriés et cliquez sur .
Vous trouverez dans les paragraphes suivants des explications sur les différentes options.
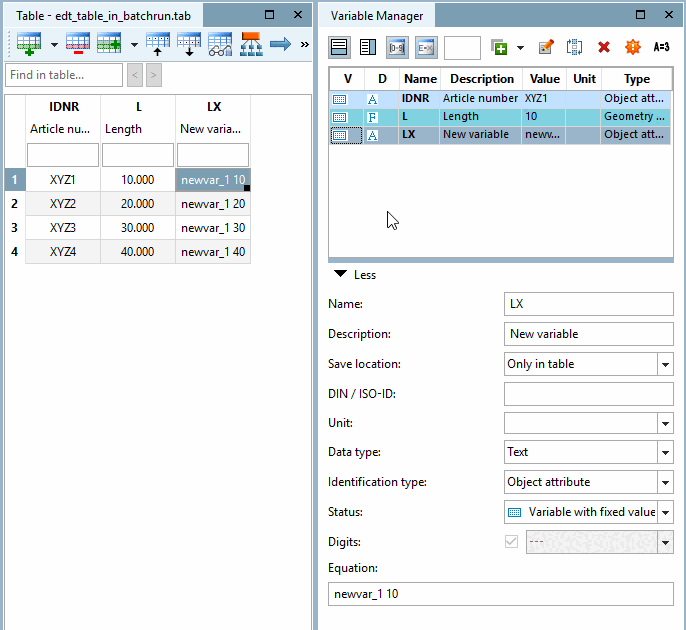
Cette fonction permet d'ajouter une nouvelle variable et de définir en même temps la valeur de la variable, mais aussi de définir des propriétés telles que la position de la colonne dans le tableau.
Sélectionnez l'option Ajouter une variable / Modifier la valeur de la variable [Add variable / change variable value].
Paramètres dans la section Critères de recherche [Search criteria]:
Sous Nom de variable [Name of variable] → Variable de table/géométrie [Table/geometry variables], saisissez le nom de la variable.
Laissez le paramètre par défaut sous Type de données [Data type] à Texte et nombre [Text and number].
Laissez le paramètre par défaut sous Types de variables [Variable types] sur Tous les types de variables [All variable types].
Paramètres dans la section Valeurs à définir [Values to set]:
Description de la variable [Variable description] (facultatif)
Identification du type [Identification type]: (voir aussi Section 7.8.14, « Identification du type »)
Emplacement [Save location]: (voir aussi Section 7.8.11, « Emplacement: Dans la géométrie uniquement | Dans le tableau uniquement | Dans la géométrie et le tableau »)
Position de la variable [Variable position]:
Par exemple, avec la position de variable [Variable position] "2", vous placez la nouvelle variable à la 2e position dans le tableau.
Valeur pour la variable [Value for variable]: une valeur fixe ou une variable peut être utilisée comme valeur.
Extrait de Valeur [Cutout from value]:
Si vous ne voulez pas utiliser toute l'expression "$NB." comme valeur variable, mais seulement une sous-chaîne, limitez par exemple aux caractères "1-5" sous Extrait de valeur [Cutout from value].
![Boîte de dialogue Modifier en traitement par lots [Edit in batch]](https://webapi.partcommunity.com/service/help/latest/pages/fr/partsolutions_user/doc/resources/img/img_15c04ecc7a73442aacdc41e64929ec5b.png)
![Exemple de description de variable [Variable description]](https://webapi.partcommunity.com/service/help/latest/pages/fr/partsolutions_user/doc/resources/img/img_70f9286cb3a040449d3e74666d5d653e.png)
→ La nouvelle variable est intégrée dans le tableau en tant que 3e colonne. La description est affichée sous le nom de la variable. La désignation de la norme a été saisie comme valeur de la variable.
![[Remarque]](https://webapi.partcommunity.com/service/help/latest/pages/fr/partsolutions_user/doc/images/note.png) | Remarque |
|---|---|
D'un point de vue fonctionnel, il n'y a pas de différence entre l'ajout d'une nouvelle variable avec une valeur souhaitée et la modification de la valeur d'une variable existante. Par conséquent, les options de paramétrage des fonctions Ajouter une variable / Modifier la valeur d' [Add variable / change variable value] une variable et Modifier la valeur d'une variable [Change value of variable] sont identiques. Comparer avec Section 5.8.2.1.20.1.1, « Ajouter une variable / Modifier la valeur d'une variable ». | |
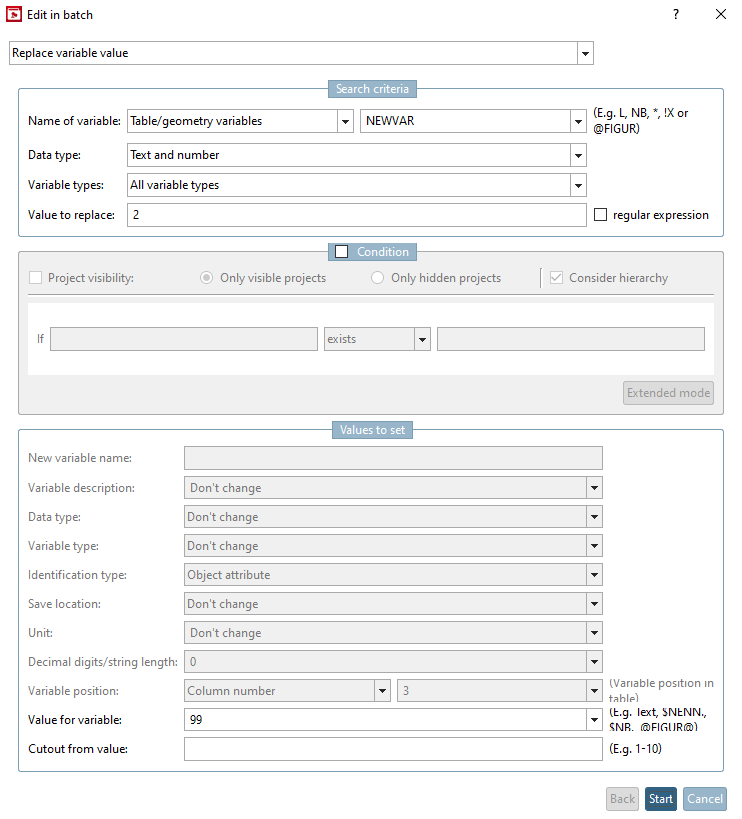
L'option Remplacer la valeur de la variable [Replace variable value] permet d'indiquer une valeur spécifique (Valeur à remplacer [Value to replace] ) comme critère de recherche.
Sélectionnez l'option Remplacer la valeur de la variable [Replace variable value].
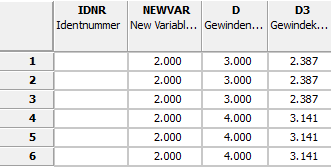
Sous Nom de la variable [Name of variable], définissez l'option souhaitée dans la première zone de liste et la variable concernée dans la deuxième zone de liste (ici, par exemple, NEWVAR).
Sous Valeur à remplacer [Value to replace], indiquez la valeur actuelle de la variable (ici "2"). (Il est également possible d'utiliser des expressions régulières si la case à cocher Expression régulière [Regular expression] est activée).
Sous Valeurs à définir [Values to set], saisissez -> Valeur pour la variable [Value for variable] la nouvelle valeur de la variable (ici "99").
Accédez au(x) fichier(s) de tableau des projets concernés.
→ La/les valeur(s) de colonne modifiée(s) est/sont reprise(s).
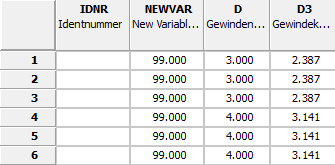
Dans la boîte de dialogue Traiter en mode batch [Edit in batch], sélectionnez l'option Supprimer les variables [Delete variables].
Nom de la variable [Name of variable]:
Dans la première zone de liste, sélectionnez l'option souhaitée parmi Variable de tableau/géométrie [Table/geometry variables], Variable de projet [Project variable] ou Autre [Other].
Sélectionnez la variable souhaitée dans la deuxième zone de liste. Vous pouvez également saisir plusieurs variables séparées par des virgules en utilisant la saisie libre.
Laissez les paramètres par défaut dans les champs Type de données [Data type] et Types de variables [Variable types].
Vous pouvez également utiliser le caractère générique "*" pour toutes les variables. Dans ce cas, vous filtrez alors via les champs Type de données [Data type] et Types de variables [Variable types].
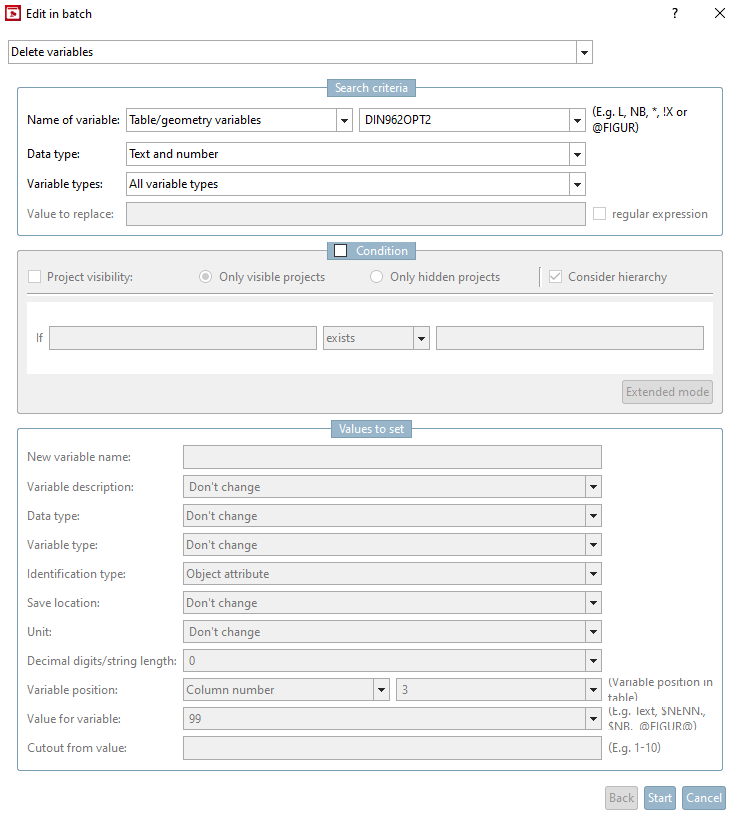
Dans la boîte de dialogue Traiter en mode batch [Edit in batch], sélectionnez l'option Renommer la variable [Rename variable]. Le cas échéant, activez également la case à cocher Adapter les références dans les assemblées [Adapt links in assemblies].
Saisissez le nom de la variable à modifier sous Critères de recherche [Search criteria] -> Nom de la variable [Name of variable].
En règle générale, vous laissez la valeur par défaut sous Type de données [Data type] et types de variables [Variable types] (Texte et nombre [Text and number], Tous les types de variables [All variable types] ).
Saisissez le nouveau nom de la variable sous Valeurs à définir [Values to set] -> Nouveau nom de variable [New variable name].
Saisissez éventuellement la nouvelle description de la variable sous Valeurs à définir [Values to set] -> Description de la [Variable description] variable.
Vous pouvez reprendre des valeurs de tableau d'un fichier CSV et/ou ajouter des variables d'un fichier CSV. La procédure est illustrée ci-dessous à l'aide d'un exemple.
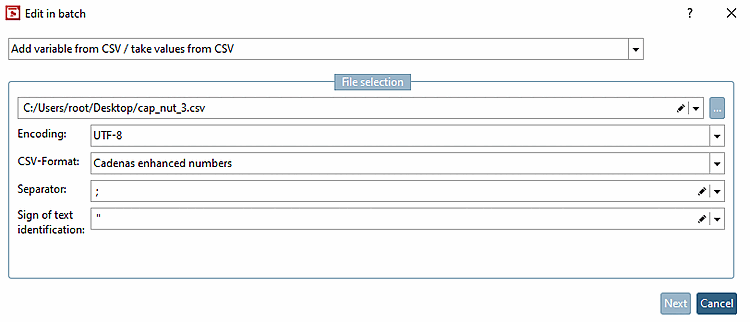
Pour une ligne, les valeurs des variables sont complètes. Les autres lignes doivent être remplies à partir du fichier CSV.
Il est également possible d'ajouter d'autres données manquantes comme l'unité [Unit] ou de corriger des données non pertinentes comme le lieu de stockage [Save location].
Mettez à disposition les valeurs souhaitées sous la forme d'un fichier CSV :
Structure requise du fichier CSV en cas de sélection de Cadenas [Cadenas standard] standard : [Cadenas standard]
Dans la ligne de type de données [Data type], utilisez "T" pour le texte et Z pour le nombre.
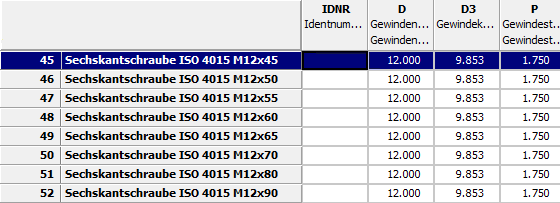
IDNR;NENN;DG;GK;DA;DK;DW;X;H;M;S;T Identifikationsnummer;Zeilenbeschreibung;Gewindenenndurchmesser;...;.....;... ;;mm;mm;mm;mm;mm;mm;mm;mm;mm;mm T;T;Z;Z;Z;Z;Z;Z;Z;Z;Z;Z 1;M4;4;3.242;4.6;6.5;5.8;1.4;8;3.2;7;5.26 2;M5;5;4.134;5.75;7.5;6.8;1.6;10;4;8;7.21 3;M6;6;4.917;6.75;9.5;8.3;2;12;5;10;7.71 4;M8;8;6.647;8.75;12.5;11.3;2.5;15;6.5;13;10.65 5;M10;10;8.376;10.8;15;14.3;3;18;8;16;12.65
Vous pouvez obtenir une telle structure du fichier CSV par exemple au moyen de la commande de menu contextuel dans l' index du catalogue PARTproject → Sortie [Output] → Créer un tableau CSV [Create CSV table].
Structure requise du fichier CSV en cas de sélection du format numérique étendu de Cadenas [Cadenas enhanced numbers]:
Dans la ligne de type de données [Data type], utilisez "A10" pour le texte, "I1" pour les entiers et "F5.1" à "F5.5" pour les nombres décimaux.
"IDNR";"NENN";"DG";"GK";"DA";"DK";"DW";"X";"H";"M";"S";"T" "Identifikationsnummer";"Zeilenbeschreibung";"Gewindenenndurchmesser";"...";.....;"..." "";"";"";"";"";"";"";"";"";"";"";"" "A10";"A10";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3" "1";"M4";"4";"3.242";"4.6";"6.5";"5.8";"1.4";"8";"3.2";"7";"5.26" "2";"M5";"5";"4.134";"5.75";"7.5";"6.8";"1.6";"10";"4";"8";"7.21" "3";"M6";"6";"4.917";"6.75";"9.5";"8.3";"2";"12";"5";"10";"7.71" "4";"M8";"8";"6.647";"8.75";"12.5";"11.3";"2.5";"15";"6.5";"13";"10.65" "5";"M10";"10";"8.376";"10.8";"15";"14.3";"3";"18";"8";"16";"12.65"
Vous pouvez obtenir une telle structure du fichier CSV par exemple dans PARTdesigner → Tableau → Enregistrer comme fichier CSV.
Sélectionnez l'option Ajouter une variable à partir du CSV/Reprendre les valeurs du CSV [Add variable from CSV / take values from CSV].
Zone de dialogue "Sélection de fichiers [File selection]
Saisissez un CSV manuellement ou sélectionnez un ou plusieurs fichiers CSV en cliquant sur le bouton Parcourir. un ou plusieurs fichiers CSV (touche Ctrl). Si plusieurs sont sélectionnés, ils sont séparés par le symbole du tube.
Il s'agit du codage du texte, généralement UTF-8, qui permet de garantir dans tous les cas que les trémas, par exemple, sont traités correctement. Avec le réglage par défaut UTF-8, cela devrait être garanti dans la plupart des cas.
Si un autre codage est nécessaire, il peut être paramétré ici (par ex. si de très anciens fichiers CSV codés ANSI et contenant des caractères spéciaux quelconques doivent être lus).
Dans le fichier CSV, seul "T" pour texte et "Z" pour nombre peuvent être indiqués.
Variable1;Variable2;Variable3;... Variable description 1;Variable description 2;Variable description 3;... ;;Einheit;Einheit;... T;T;Z;Z;Z;Z;Z;Z;Z;Z;Z;Z Daten Daten ...Pour chaque nombre, "Nombre décimal (0.123)" est automatiquement saisi, car c'est la valeur par défaut des nombres décimaux dans PSOL. Si vous ouvrez la zone de liste dans le dialogue, vous pouvez toutefois procéder aux adaptations suivantes :
Utilisé par exemple pour une exportation lorsque l'on exécute dans PARTproject sur un projet la commande de menu contextuel Sortie [Output] → Créer une table CSV [Create CSV table].
Le format numérique étendu de Cadena [Cadenas enhanced numbers]
4ème ligne : Type de données, mais ici avec représentation PSOL VIDA
Variable1;Variable2;Variable3;... Variable description 1;Variable description 2;Variable description 3;... ;;Einheit;Einheit;... "A10";"A10";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3" Daten Daten ...Toutes les autres lignes contiennent les données.
La structure des données est donc la même que celle de Cadenas standard, à l'exception du type de données.
Utilisé par exemple dans PARTdesigner, lorsque l'on clique sur Enregistrer en tant que fichier CSV [Save as CSV file] dans le tableau.
Pas de format spécifique [No specific format]
Ce format ne permet pas de définir la description, l'unité ou le type de données. Il s'agit toujours de texte et ne doit donc être utilisé que si aucune autre information n'est disponible.
Détection automatique [Try to detect]
Le système tente ici de reconnaître l'un des deux formats CADENAS. S'il n'y parvient pas, l'option Aucun format particulier [No specific format] est utilisée.
Indique le caractère utilisé pour séparer les colonnes les unes des autres dans le CSV. Contexte : en Allemagne, une virgule est utilisée pour séparer les chiffres décimaux après la virgule ; une virgule ne pourrait donc pas être utilisée comme séparateur de colonnes. Comme différents exportateurs créent des CSV avec des séparateurs différents, cela peut être configuré ici en conséquence pour être lu correctement.
Le signe d'identification du texte [Sign of text identification] est similaire.
Le CSV est maintenant importé et on est redirigé vers la page de dialogue suivante, dans laquelle les informations chargées à partir du CSV peuvent être adaptées et étendues.
Zone de dialogue "Paramètres dépendants des colonnes [Column Settings]
Adaptez-les en conséquence si nécessaire.
Cochez la case de toutes les variables pour lesquelles vous souhaitez effectuer des modifications.
Colonne d'identification [Identifying Column] / nom de variable dans le catalogue [Variable name in the catalog]:
Déterminez la variable par laquelle vous souhaitez établir la correspondance entre le fichier CSV et le catalogue. Toutes les colonnes (variables) du fichier CSV sont affichées dans la zone de liste de Colonne d'identification [Identifying Column].
(Dans l'exemple ci-dessus, le mapping est établi via la variable "IDNR". Dans la pratique, il s'agit généralement de la variable du numéro d'identification. Si le numéro d'identification est unique, l'affectation au bon projet peut être établie sans problème même si plusieurs fichiers CSV sont utilisés).
Saisissez dans le champ de saisie du nom de la variable dans le catalogue [Variable name in the catalog] la variable par laquelle vous souhaitez établir la correspondance entre le fichier CSV et le catalogue.
Sur la base de la correspondance entre la colonne d'identification [Identifying Column] et le nom de la variable dans le catalogue [Variable name in the catalog], les données peuvent être attribuées à la bonne ligne.
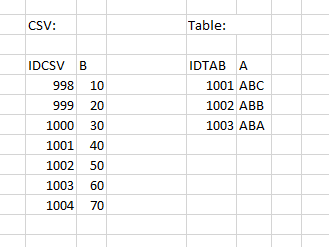
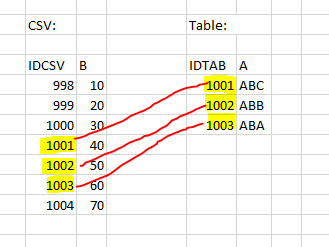
Petit exemple: le CSV a les colonnes "IDCSV" et "B" ; le tableau a les colonnes "IDTAB" et "A". Il faut maintenant ajouter la variable "B" du CSV dans le tableau. Or, le CSV comporte beaucoup plus de lignes.
Si vous choisissez maintenant IDCSV comme "colonne d'identification [Identifying Column]" et IDTAB comme "nom de variable dans le catalogue [Variable name in the catalog]", les 3 valeurs correctes de B peuvent ainsi être ajoutées au tableau, à savoir exactement là où IDCSV et IDTAB ont la même valeur.
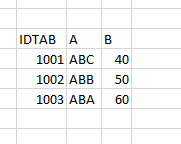
Le tableau rempli se présente alors comme suit.
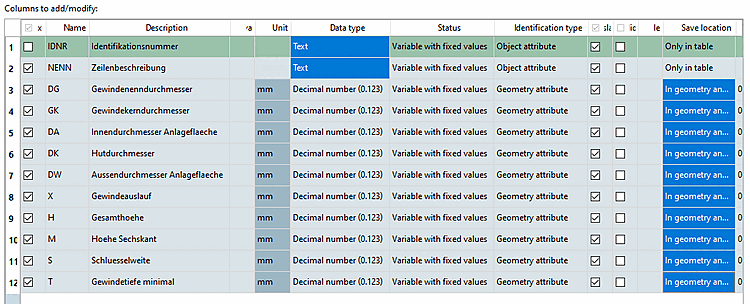
Colonnes à modifier/ajouter [Columns to add/modify]:
La signification des différentes colonnes du tableau est expliquée ci-dessous :
La case à cocher: Cochez la case des variables dont vous souhaitez modifier les valeurs.
Vous pouvez activer ou désactiver toutes les variables à l'aide de la case à cocher dans l'en-tête de la colonne (x).
Description: Description de la variable qui s'affiche dans le tableau sous le nom de la variable.
Variable de table [Table variables]: saisissez ici un nom si la variable doit être copiée du CSV dans la table, mais doit y porter un autre nom. Si le champ est vide, le nom est repris du CSV (colonne "Nom").
Cette indication est également prise en compte lors de la vérification des noms. Si le nom de la variable dans le CSV n'est pas valable pour la table (caractères non autorisés), vous pouvez soit l'adapter, soit donner un autre nom à la table et laisser le nom original non valable.
Unité [Unit]: l'unité est affichée dans l'en-tête de la colonne, entre crochets, après la description de la variable. La valeur peut être adaptée, mais peut aussi être vide.
Si l'option Cadenas standard a été sélectionnée dans la première boîte de dialogue sous Format CSV [CSV-Format], qui n'autorise que du texte ou un nombre, "Nombre décimal (0.123)" est automatiquement saisi ici pour chaque nombre (ce qui est la valeur par défaut pour les nombres décimaux dans PSOL).
Si l'option Format numérique étendu de Cadena [Cadenas enhanced numbers] a été sélectionnée dans la première boîte de dialogue sous Format CSV [CSV-Format], la représentation correspond exactement à la valeur par défaut différenciée du CSV.
Dans les deux cas, lorsque vous ouvrez la zone de liste, vous pouvez éventuellement adapter le format.
État [Status]: sélectionnez l'option souhaitée dans la zone de liste.
Variable à valeur fixe [Variable with fixed values] (par défaut) : chaque ligne du tableau a sa propre valeur pour cette variable.
Variable de plage de valeurs [Value range variable]: syntaxe équivalente à celle du gestionnaire de variables [Variable Manager] PARTdesigner.
Algorithme des caractéristiques [Attribute algorithm]: syntaxe équivalente à PARTdesigner Gestionnaire de variables [Variable Manager]
![[Important]](https://webapi.partcommunity.com/service/help/latest/pages/fr/partsolutions_user/doc/images/important.png)
Important Pour les variables de plage de valeurs et les algorithmes de caractéristiques, chaque ligne n'a pas sa propre valeur, mais chacune contient quasiment le même algorithme (ou plage de valeurs). Le résultat de l'algorithme peut toutefois être différent dans chaque ligne.
Ici, dans le CSV, chaque ligne contient le même algorithme/plage de valeurs.
Identification du type [Identification type]: équivalent de PARTdesigner Gestionnaire de variables [Variable Manager]
Traduire la [Translation] variable : Déterminez par une case à cocher si la variable en question doit être ajoutée ou non à celles à traduire dans le projet.
Cacher la [Hide] variable : Déterminez par une case à cocher si la variable en question doit être cachée ou non dans le projet.
Affectation à un groupe [Variable group]: déterminez ici en option l'appartenance d'une variable à un groupe dans le projet.
En principe, une variable peut être contenue dans plusieurs groupes. Pour cela, inscrivez une liste séparée par des virgules.
Avec le préfixe " !", la variable concernée peut également être supprimée des groupes.
GRUPPE1,!GRUPPE2,GRUPPE4
Mit diesem Wert wird die Variable in den Gruppen "GRUPPE1" und "GRUPPE4" hinzugefügt und aus "GRUPPE2" entfernt.
Remarque Les groupes doivent exister dans le catalogue !
Comme l'utilisateur ne peut pas forcément modifier le nœud racine du catalogue lors de l'édition par lot (parce qu'il n'a peut-être pas les droits SVN pour cela), le système indique éventuellement à la fin de l'exécution du lot quels groupes ont été ajoutés récemment et doivent encore être ajoutés manuellement au catalogue.
Emplacement [Save location]: équivalent du gestionnaire de variables [Variable Manager] PARTdesigner
Valeur par défaut [Default value]: cette colonne indique une valeur par défaut au cas où aucune ligne correspondant à l'identifiant n'est trouvée dans le CSV.
Si, dans l'exemple ci-dessus, la table contenait une autre ligne avec une valeur IDTAB de 1022, celle-ci ne serait pas trouvée dans le CSV (car IDCSV ne possède pas une telle valeur) et la valeur ne pourrait donc pas être transmise.
Dans ce cas, la valeur par défaut est utilisée. Si aucune valeur par défaut n'est indiquée, une valeur par défaut interne (petit nombre "inesthétique") est utilisée comme fallback.
Ajouter des colonnes si elles n'existent pas encore [Add columns if non existent]: Si l'option est activée, les colonnes de variables sont éventuellement créées dans le tableau si elles n'y existent pas encore.
Dans l'exemple ci-dessus, cette case à cocher devrait être activée, car "B" n'existait pas auparavant dans le tableau.
Si cette case n'est pas cochée, seules les valeurs des tableaux qui contiennent déjà cette variable seront adaptées.
Ne créer des colonnes que si des données existent pour la table [Only create columns if there are table data available]: Cette option évite de créer une variable dans un tableau si aucune ligne d'identifiant ne correspond.
Ainsi, dans l'exemple ci-dessus, si aucune valeur d'IDTAB n'est trouvée dans le CSV sous IDCSV, la variable ne sera pas créée.
Zone de dialogue "Condition": (équivalent de la condition dans les autres modes d'exécution par lots)
Il est possible de définir ici des conditions de base pour l'exécution par lots. Par exemple, que seuls les projets visibles soient traités ou que seuls les projets invisibles soient traités.
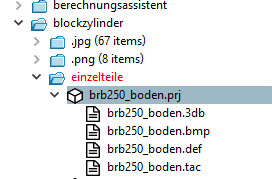
Case à cocher Prendre en compte la hiérarchie [Consider hierarchy]: La structure des dossiers est prise en compte. PAR EX : Je ne veux traiter que les projets visibles. Il se peut qu'un projet soit lui-même visible, mais qu'un répertoire situé au-dessus soit caché.
brb250_boden.prjest elle-même visible, mais le répertoireeinzelteileest masqué.Si l'option Seulement les projets visibles [Only visible projects] est sélectionnée et que la case Prendre en compte la hiérarchie [Consider hierarchy] N'EST PAS cochée, le projet sera traité car il est visible. Mais si la case Prendre en compte la hiérarchie [Consider hierarchy] est cochée, le projet ne sera pas traité car un répertoire est caché au-dessus. Le système vérifie donc également si un répertoire situé au-dessus (jusqu'au nœud racine du catalogue) est caché.
Le bouton permet de revenir à la première boîte de dialogue, où l'on peut sélectionner le fichier CSV.
Le bouton démarre le traitement par lots.
Le bouton permet de quitter la boîte de dialogue Modifier en traitement par lots [Edit in batch] sans rien faire.
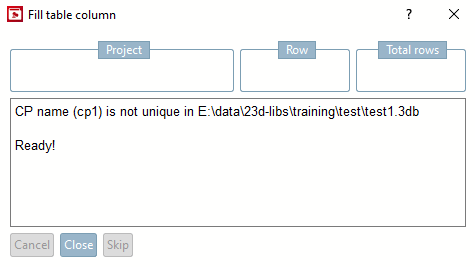
→ La boîte de dialogue Remplir la colonne du tableau [Fill table column] indique la progression.
→ Les valeurs manquantes ont été importées en conséquence.
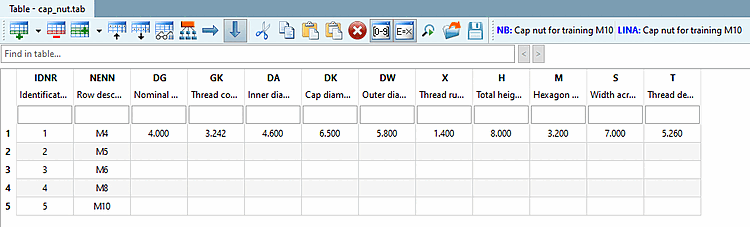
![Créer un tableau CSV [Create CSV table]](https://webapi.partcommunity.com/service/help/latest/pages/fr/partsolutions_user/doc/resources/img/img_63e51e35e1dc45e4a4f8c750e0c48aab.png)
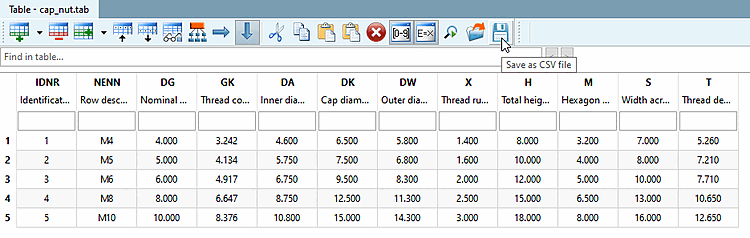
![Fenêtre Modifier en traitement par lots [Edit in batch]](https://webapi.partcommunity.com/service/help/latest/pages/fr/partsolutions_user/doc/resources/img/img_e4d325ad735b4d22bfddc161d1eb2933.png)
![Paramètres dépendant des colonnes [Column Settings]](https://webapi.partcommunity.com/service/help/latest/pages/fr/partsolutions_user/doc/resources/img/img_c169f786b44e46dbbcbc4354f75230d1.png)
![Fenêtre Remplir une colonne de tableau [Fill table column]](https://webapi.partcommunity.com/service/help/latest/pages/fr/partsolutions_user/doc/resources/img/img_5c91622500844ef58faa1df60dc45980.png)
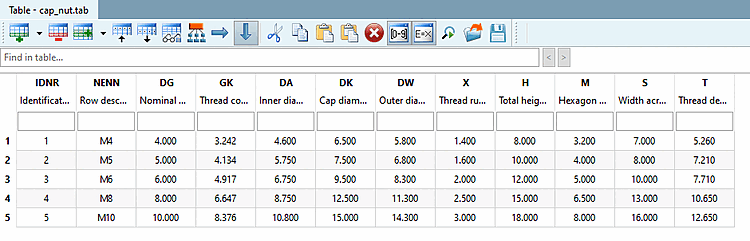
Le tableau suivant montre les possibilités de saisie dans le champ Nom de la variable [Name of variable].
|
Les mots-clés servent à la communication interne des données entre PARTproject et PARTdataManager. Vous pouvez consulter les mots-clés existants en ouvrant le fichier de projet correspondant (dans le répertoire "23d-libs") avec un éditeur de texte. Les mots-clés sont listés à gauche du signe égal (ici : TYPE, PROJET, SHORTNAME, etc.). Les mots-clés permettent également - et c'est important ici dans le cadre de la fonction Traiter par lots [Edit in batch] - d'utiliser des noms de variables auxquels il est possible d'attribuer des valeurs fixes ou des valeurs d'autres variables. |
|
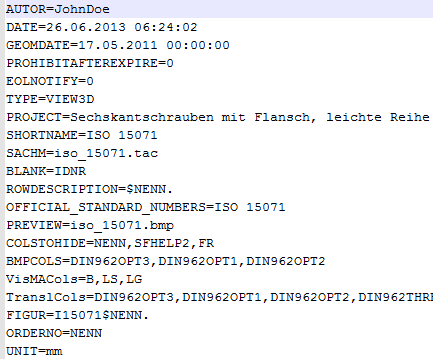
Nous allons illustrer cela par l'exemple du mot-clé du champ Description de la ligne [Row label].
Il s'appelle ROWDESCRIPTION et contrôle l'affichage de la colonne correspondante dans le tableau du PARTdataManager. Actuellement, la colonne contient des valeurs selon "$NENN" (voir fichier de projet).
Pour attribuer de nouvelles valeurs à cette colonne, procédez comme suit : |
| ||||
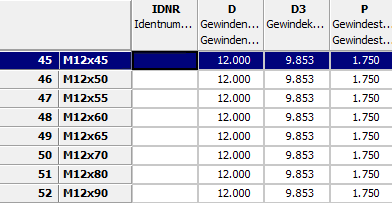
Sélectionnez l'option Remplacer la valeur de la variable [Replace variable value].
Sous Critères de recherche [Search criteria] -> Nom de la variable [Name of variable] dans la première zone de liste, sélectionnez Variable de projet [Project variable] et dans la deuxième zone de liste l’option
ROWDESCRIPTION.Sous Critères de recherche [Search criteria] , entrez Valeur à remplacer [Value to replace]
$NENN..Sous Valeurs à définir [Values to set], entrez Valeur pour la variable [Value for variable]
$NB.Un.
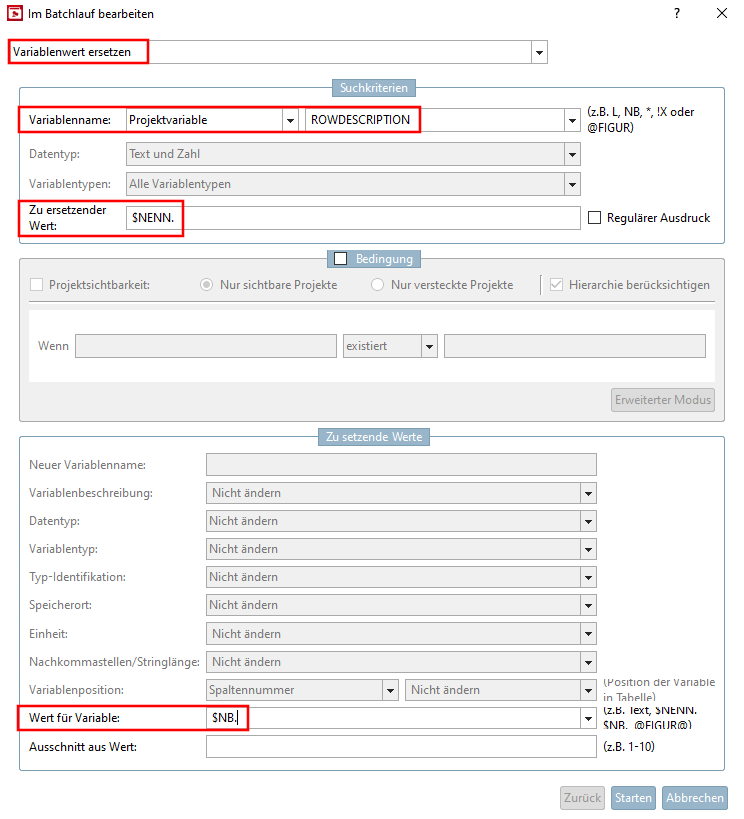
-> Dans le PARTdataManager, la nouvelle description de ligne NB remplace désormais NENN.
En particulier pour les projets avec de nombreux 3dbs ou des points d'attache toujours nécessaires, certains sketches sont utilisés plusieurs fois, ce qui est très fastidieux à copier. La copie de sketches par lots est beaucoup plus simple et permet de gagner du temps.
Avec la fonction Editer en traitement par lots [Edit in batch], option Insérer un plan/une [Add plane/sketch] esquisse, un plan ou une esquisse sélectionné(e) est ajouté(e) dans tous les projets et dans tous les 3dbs.
Le nouveau sketch est ajouté à l' historique 3D [3D History] avec un numéro séquentiel.
Enregistrez le sketch à copier (fichier *.hsk) à l'endroit de votre choix.
Ouvrez au-dessus du même projet (pour y copier dans tous les 3dbs), d'un autre projet ou d'un répertoire la commande de menu contextuel Automatisation [Automation] -> Modifier le projet en traitement par lots [Edit project in batch mode].
-> La boîte de dialogue Modifier en traitement par lots [Edit in batch] s'ouvre.
Sélectionnez l'option Insérer un plan/une esquisse [Add plane/sketch] dans la zone de liste supérieure.
Choisir l'esquisse [Select sketch]: Cliquez sur le bouton le fichier et indiquez le chemin d'accès au fichier de l'esquisse.
Plan de référence [Reference plane]: Saisir le nom du plan de référence sur lequel l'esquisse doit être insérée.
Si le plan de référence n'existe pas [If reference plane does not exist]: Sélectionnez soit l'option Ne pas insérer l'esquisse [Do not add sketch], soit un plan spécifique.
-> Le sketch est inséré dans tous les 3dbs de chaque projet souhaité.
![Insérer un sketch [Insert sketch]](https://webapi.partcommunity.com/service/help/latest/pages/fr/partsolutions_user/doc/resources/img/img_22ce6919bb564eb884ea01bb476927e7.png)