- 5.8.2.1.20.1.1. Aggiungere una variabile / modificare il valore della variabile
- 5.8.2.1.20.1.2. Modifica del valore della variabile
- 5.8.2.1.20.1.3. Sostituire il valore della variabile
- 5.8.2.1.20.1.4. Cancellare le variabili
- 5.8.2.1.20.1.5. Rinominare la variabile
- 5.8.2.1.20.1.6. Aggiungere variabili da CSV/adottare valori da CSV
- 5.8.2.1.20.1.7. Opzioni di immissione nel campo "Nome della variabile
- 5.8.2.1.20.1.8. Utilizzo di parole chiave
- 5.8.2.1.20.1.9. Inserire il livello/lo schizzo
Le tabelle degli attributi caratteristici assegnati alle singole parti/progetti di un catalogo possono essere modificate tramite l'elaborazione batch.
Esistono diverse opzioni per modificare le variabili della tabella. La modalità desiderata viene selezionata nel campo dell'elenco superiore:
Aggiungere una variabile / modificare il valore della variabile [Add variable / change variable value]
Modifica del valore della variabile [Change value of variable]
Sostituire il valore della variabile [Replace variable value]
Aggiungere variabili da CSV/adottare valori da CSV [Add variables from CSV / change variable values from CSV]
A seconda dell'opzione selezionata, sono attivi i campi di immissione corrispondenti nelle sezioni Criteri di ricerca [Search criteria] e Valori da impostare [Values to set].
![Modifica nell'esecuzione batch [Edit in batch]](https://webapi.partcommunity.com/service/help/latest/pages/it/partsolutions_user/doc/resources/img/img_a6e79483d3234b04ab742a3825ec085c.png)
Effettuare le impostazioni appropriate e fare clic su .
Le spiegazioni delle singole opzioni sono riportate nelle sezioni seguenti.
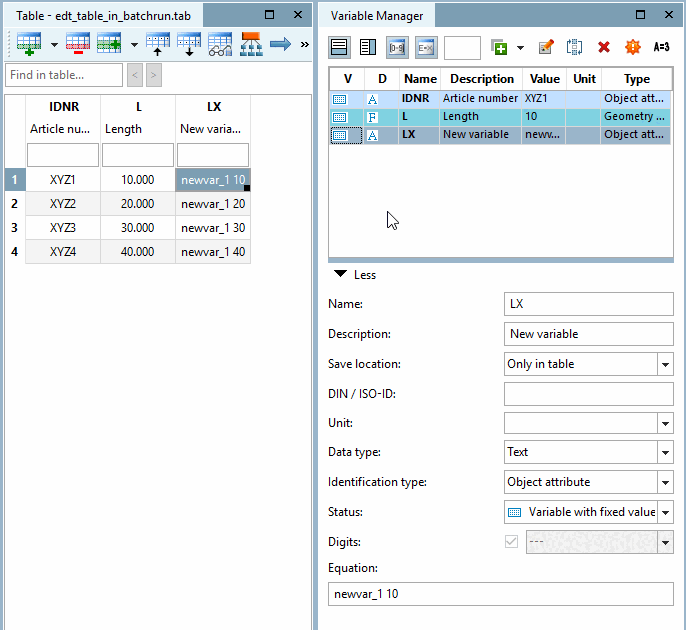
La funzione consente di aggiungere una nuova variabile e di impostarne contemporaneamente il valore, ma anche di impostare proprietà come la posizione della colonna all'interno della tabella.
Selezionare l'opzione Aggiungi variabile / Modifica valore variabile [Add variable / change variable value].
Figura 5.266. Modifica nella [Edit in batch] finestra di dialogo dell'esecuzione batch [Edit in batch]
Impostazioni nella sezione Criteri di ricerca [Search criteria]:
Inserire il nome della variabile in Nome variabile [Name of variable] → Variabile tabella/geometria [Table/geometry variables].
Lasciare l'impostazione predefinita in Tipo di dati [Data type] come Testo e Numero [Text and number].
Lasciare l'impostazione predefinita in Tipi di variabili [Variable types] come Tutti i tipi di variabili [All variable types].
Impostazioni nella sezione Valori da impostare [Values to set]:
Descrizione della variabile [Variable description] (opzionale)
Sezione 7.8.14, “ Identificazione del tipo ”I dentificazione del tipo [Identification type]: (vedi anche )
Sezione 7.8.11, “ Posizione di memorizzazione: Solo nella geometria | Solo nella tabella | Nella geometria e nella tabella ”L uogo di stoccaggio [Save location]: (vedi anche )
Posizione variabile [Variable position]:
Con la posizione della variabile [Variable position] "2", ad esempio, si imposta la nuova variabile nella seconda posizione della tabella.
Valore per variabile [Value for variable]: come valore si può usare sia un valore fisso che una variabile.
Estratto da Wert [Cutout from value]:
Se non si desidera utilizzare l'intera espressione "$NB." come valore della variabile, ma solo una sottostringa, limitare la sezione del valore [Cutout from value] ai caratteri "1-5", ad esempio.
![Modifica nella [Edit in batch] finestra di dialogo dell'esecuzione batch [Edit in batch]](https://webapi.partcommunity.com/service/help/latest/pages/it/partsolutions_user/doc/resources/img/img_69c7cb42b70749cea6490a9350503ef5.png)
![Esempio di descrizione [Variable description] di una variabile [Variable description]](https://webapi.partcommunity.com/service/help/latest/pages/it/partsolutions_user/doc/resources/img/img_b1f04ac71cd14bd484b07517a0dcc271.png)
→ La nuova variabile viene integrata nella tabella come terza colonna. La descrizione viene visualizzata sotto il nome della variabile. La denominazione standard è stata inserita come valore della variabile.
![[Nota]](https://webapi.partcommunity.com/service/help/latest/pages/it/partsolutions_user/doc/images/note.png) | Nota |
|---|---|
Dal punto di vista funzionale, non vi è alcuna differenza tra l'aggiunta di una nuova variabile con un valore desiderato e la modifica del valore di una variabile esistente. Le opzioni di impostazione delle funzioni Aggiungi variabile / Modifica valore variabile [Add variable / change variable value] e Modifica valore variabile [Change value of variable] sono pertanto identiche. Sezione 5.8.2.1.20.1.1, “ Aggiungere una variabile / modificare il valore della variabile ”Confronta . | |
L'opzione Sostituisci valore variabile [Replace variable value] consente di specificare un valore specifico (Valore da sostituire [Value to replace] ) come criterio di ricerca.
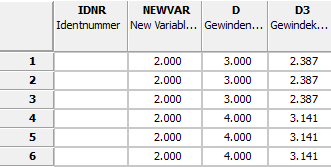
Selezionare l'opzione Sostituisci valore variabile [Replace variable value].
In Nome variabile [Name of variable], specificare l'opzione desiderata nel primo campo dell'elenco e la relativa variabile nel secondo campo dell'elenco (qui NEWVAR come esempio).
In Valore da sostituire [Value to replace], inserire il valore corrente della variabile (qui "2"). (È possibile utilizzare anche le espressioni regolari se la casella di controllo Espressione regolare [Regular expression] è attivata).
In Valori da impostare [Values to set] -> Valore per la variabile [Value for variable] inserire il nuovo valore della variabile (qui "99").
Richiamare i file di tabella dei progetti interessati.
→ Il valore o i valori della colonna modificati sono stati accettati.
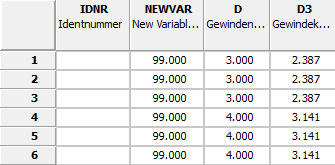
Nella finestra di dialogo Modifica nell'esecuzione batch [Edit in batch], selezionare l'opzione Elimina variabili [Delete variables].
Nome della variabile [Name of variable]:
Nel primo campo dell'elenco, selezionare l'opzione desiderata tra Variabile tabella/geometria [Table/geometry variables], Variabile progetto [Project variable] o Altro [Other].
Selezionare la variabile desiderata nel secondo campo elenco. È anche possibile inserire più variabili separate da virgole.
Lasciare le impostazioni predefinite nei campi Tipo di dati [Data type] e Tipi di variabili [Variable types].
In alternativa, si può anche impostare il segnaposto "*" per tutte le variabili. In questo caso, si filtra utilizzando i campi Tipo di dati [Data type] e Tipi di variabili [Variable types].
→ La variabile o le variabili sono state rimosse dalla tabella.
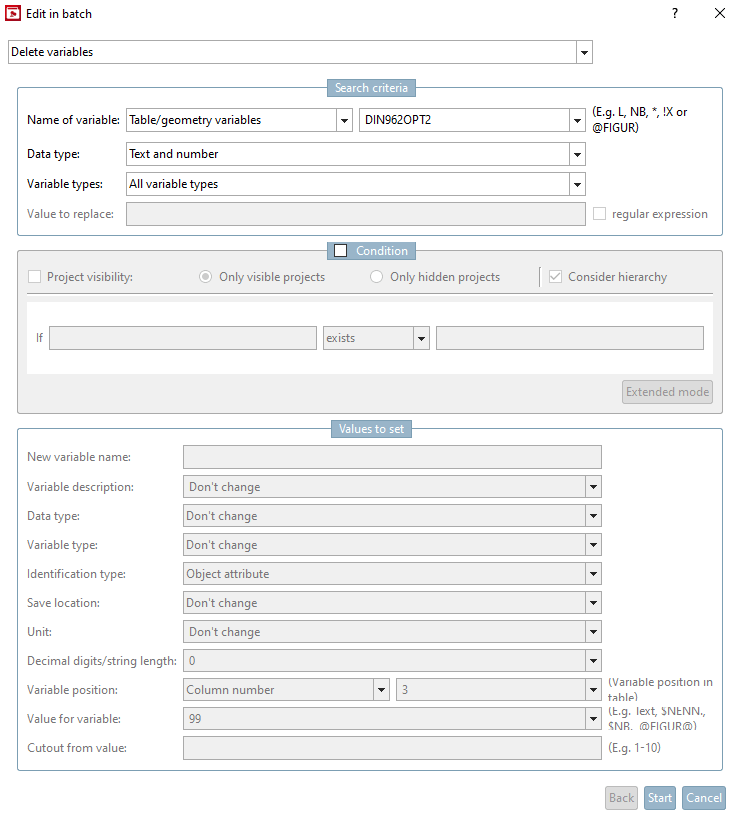
Nella finestra di dialogo Modifica nell'esecuzione batch [Edit in batch], selezionare l'opzione Rinomina variabile [Rename variable]. Se necessario, attivare anche la casella di controllo Adatta i riferimenti negli assiemi [Adapt links in assemblies].
Inserire il nome della variabile da modificare in Criteri di ricerca [Search criteria] -> Nome della variabile [Name of variable].
Di norma, lasciare l'impostazione predefinita in Tipo di dati [Data type] e tipi di variabili [Variable types] (Testo e numero [Text and number], Tutti i tipi di variabili [All variable types] ).
Inserire il nuovo nome della variabile in Valori da impostare [Values to set] -> Nuovo nome della variabile [New variable name].
In alternativa, inserire la nuova descrizione della variabile in Valori da impostare [Values to set] -> Descrizione della variabile [Variable description].
È possibile trasferire i valori delle tabelle da un file CSV e/o aggiungere variabili da un file CSV. Il processo è illustrato di seguito con un esempio.
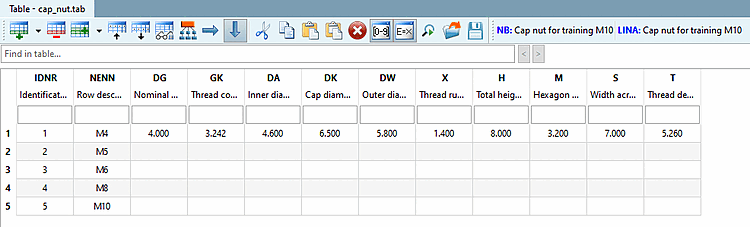
I valori delle variabili sono completi per una riga. Le righe rimanenti devono essere riempite dal file CSV.
È inoltre possibile aggiungere ulteriori dettagli mancanti, come l' unità di misura [Unit], o correggere dettagli errati, come il luogo di stoccaggio [Save location].
Fornire i valori desiderati sotto forma di file CSV:
Struttura richiesta del file CSV quando si seleziona lo standard CADENAS [Cadenas standard]:
Nella riga del tipo di dati [Data type], utilizzare "T" per testo e Z per numero.
IDNR;NENN;DG;GK;DA;DK;DW;X;H;M;S;T Identifikationsnummer;Zeilenbeschreibung;Gewindenenndurchmesser;...;.....;... ;;mm;mm;mm;mm;mm;mm;mm;mm;mm;mm T;T;Z;Z;Z;Z;Z;Z;Z;Z;Z;Z 1;M4;4;3.242;4.6;6.5;5.8;1.4;8;3.2;7;5.26 2;M5;5;4.134;5.75;7.5;6.8;1.6;10;4;8;7.21 3;M6;6;4.917;6.75;9.5;8.3;2;12;5;10;7.71 4;M8;8;6.647;8.75;12.5;11.3;2.5;15;6.5;13;10.65 5;M10;10;8.376;10.8;15;14.3;3;18;8;16;12.65
È possibile ottenere tale struttura del file CSV, ad esempio, utilizzando il comando del menu contestuale nel catalogo PARTproject index → Output → Create CSV table.
Struttura richiesta del file CSV quando si seleziona il formato del numero esteso di CADENAS [Cadenas enhanced numbers]:
Nella riga del tipo di dati [Data type], utilizzare "A10" per il testo, "I1" per i numeri interi e da "F5.1" a F5.5" per i numeri decimali.
"IDNR";"NENN";"DG";"GK";"DA";"DK";"DW";"X";"H";"M";"S";"T" "Identifikationsnummer";"Zeilenbeschreibung";"Gewindenenndurchmesser";"...";.....;"..." "";"";"";"";"";"";"";"";"";"";"";"" "A10";"A10";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3" "1";"M4";"4";"3.242";"4.6";"6.5";"5.8";"1.4";"8";"3.2";"7";"5.26" "2";"M5";"5";"4.134";"5.75";"7.5";"6.8";"1.6";"10";"4";"8";"7.21" "3";"M6";"6";"4.917";"6.75";"9.5";"8.3";"2";"12";"5";"10";"7.71" "4";"M8";"8";"6.647";"8.75";"12.5";"11.3";"2.5";"15";"6.5";"13";"10.65" "5";"M10";"10";"8.376";"10.8";"15";"14.3";"3";"18";"8";"16";"12.65"
È possibile ottenere tale struttura del file CSV, ad esempio, in PARTdesigner → Tabella → Salva come file CSV.
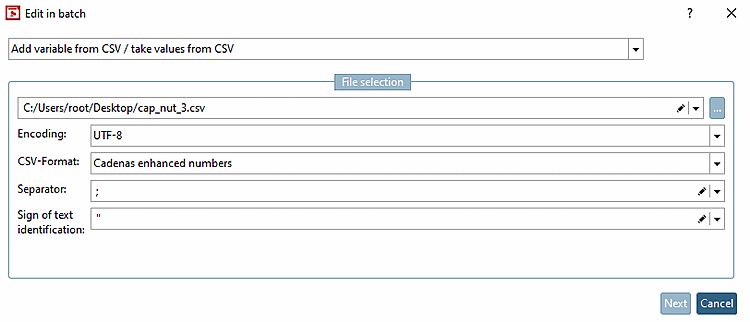
Selezionare l'opzione Aggiungi variabile da CSV/Accetta valori da CSV [Add variable from CSV / take values from CSV].
Area di dialogo "Selezione file [File selection]":
Immettere un CSV manualmente o utilizzare il pulsante Sfoglia... per selezionare uno o file CSV. per selezionare uno o più file CSV (tasto Ctrl). Se vengono selezionati più file, questi vengono separati con il simbolo del tubo.
Si riferisce alla codifica del testo, di solito UTF-8, che assicura che gli umlaut, ad esempio, siano gestiti correttamente. Con l'impostazione predefinita UTF-8, questo dovrebbe essere garantito nella maggior parte dei casi.
Se è richiesta una codifica diversa, è possibile impostarla qui (ad esempio, se si devono leggere file CSV molto vecchi con codifica ANSI e contenenti caratteri speciali).
Standard CADENAS [Cadenas standard]
Nel file CSV è possibile inserire solo "T" per testo e "Z" per numero.
Variable1;Variable2;Variable3;... Variable description 1;Variable description 2;Variable description 3;... ;;Einheit;Einheit;... T;T;Z;Z;Z;Z;Z;Z;Z;Z;Z;Z Daten Daten ...Per ogni numero viene inserito automaticamente "Numero decimale (0,123)", che è il valore predefinito per i numeri decimali in PSOL. Tuttavia, se si apre il campo elenco nella finestra di dialogo, è possibile apportare le seguenti modifiche:
Viene utilizzato, ad esempio, per un'esportazione se si esegue il comando del menu contestuale Output → Crea tabella CSV [Create CSV table] su un progetto in PARTproject.
Formato numerico esteso di CADENAS [Cadenas enhanced numbers]
Quarta riga: Tipo di dati, ma qui con rappresentazione PSOL VIDA
Variable1;Variable2;Variable3;... Variable description 1;Variable description 2;Variable description 3;... ;;Einheit;Einheit;... "A10";"A10";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3" Daten Daten ...Tutte le altre righe contengono i dati.
La struttura dei dati è quindi la stessa dello standard CADENAS [Cadenas standard], tranne che per il tipo di dati.
Viene utilizzato in PARTdesigner, ad esempio, se si fa clic su Salva come file CSV [Save as CSV file] nella tabella.
Nessun formato specifico [No specific format]
Questo formato non offre la possibilità di specificare una descrizione, un'unità o un tipo di dati. Si tratta sempre di un testo e deve quindi essere utilizzato solo se non sono disponibili altre informazioni.
Riconoscimento automatico [Try to detect]
Si cerca di riconoscere uno dei due formati di CADENAS. Se non si riesce, viene utilizzata l'opzione Nessun formato specifico [No specific format].
Specifica il carattere utilizzato per separare le colonne nel CSV. Premessa: in Germania la virgola viene utilizzata per separare i numeri decimali; pertanto, non può essere utilizzata come separatore di colonne. Poiché diversi esportatori creano CSV con separatori diversi, è possibile impostare questo carattere di conseguenza per poterlo leggere correttamente.
L' identificatore di testo [Sign of text identification] è simile.
Il CSV viene ora letto e si passa alla pagina di dialogo successiva, dove le informazioni caricate dal CSV possono essere nuovamente modificate e ampliate.
Area di dialogo "Impostazioni dipendenti dalla colonna [Column Settings]":
Se necessario, regolarli di conseguenza.
Attivare la casella di controllo per tutte le variabili che si desidera modificare.
Identificazione del [Identifying Column] nome [Variable name in the catalog] della [Identifying Column] colonna/variabile nel catalogo [Variable name in the catalog]:
Specificare la variabile che si desidera utilizzare per creare l'assegnazione tra il file CSV e il catalogo. Tutte le colonne (variabili) del file CSV vengono visualizzate nel campo Elenco colonne identificative [Identifying Column].
(Nell'esempio precedente, la mappatura viene creata tramite la variabile "IDNR". In pratica, questa sarà di solito la variabile del numero di identificazione. Con un numero di identificazione unico, la mappatura al progetto corretto può essere facilmente stabilita anche quando si utilizzano diversi file CSV).
Nel campo di immissione Nome variabile nel catalogo [Variable name in the catalog], inserire la variabile che si desidera utilizzare per creare l'assegnazione tra il file CSV e il catalogo.
I dati possono essere assegnati alla riga corretta in base all'assegnazione tra la colonna di identificazione [Identifying Column] e il nome della variabile nel catalogo [Variable name in the catalog].
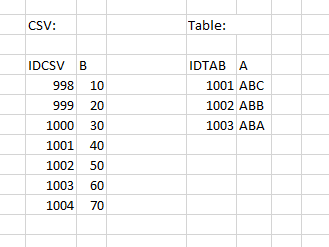
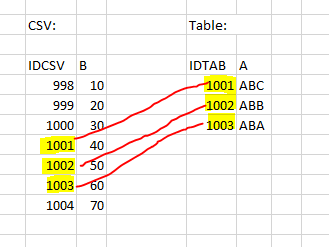
Piccolo esempio: il CSV ha le colonne "IDCSV" e "B"; la tabella ha le colonne "IDTAB" e "A". La variabile "B" deve essere aggiunta alla tabella dal CSV. Tuttavia, il CSV ha molte più righe.
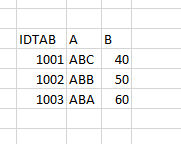
Se ora si seleziona IDCSV come "Colonna identificativa [Identifying Column]" e IDTAB come "Nome della variabile nel catalogo [Variable name in the catalog]", è possibile aggiungere alla tabella i 3 valori corretti di B, ovvero esattamente dove IDCSV e IDTAB hanno lo stesso valore.
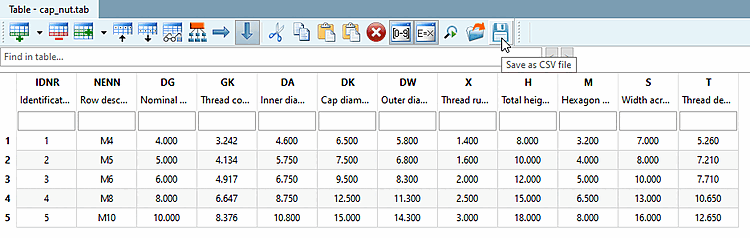
Di conseguenza, la tabella riempita si presenta come segue.
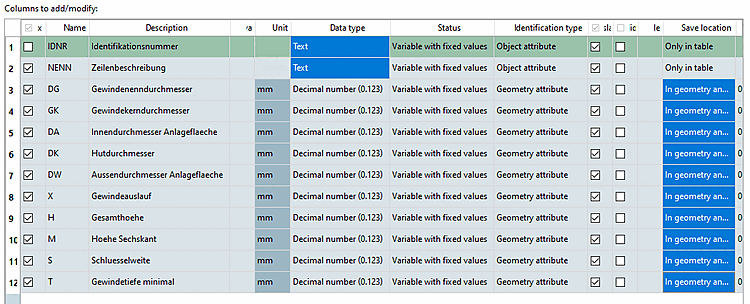
Colonne da modificare/aggiungere [Columns to add/modify]:
Di seguito viene spiegato il significato delle singole colonne della tabella:
Casella di selezione: Attivare la casella di controllo per le variabili di cui si desidera modificare i valori.
È possibile attivare o disattivare tutte le variabili utilizzando le caselle di controllo nell'intestazione della colonna (x).
Descrizione [Description]: descrizione della variabile che viene visualizzata nella tabella sotto il nome della variabile.
Variabile di tabella [Table variables]: inserire un nome se la variabile deve essere copiata dal CSV alla tabella, ma deve avere un nome diverso. Se il campo è vuoto, viene copiato il nome dal CSV (colonna "Nome").
Questa informazione viene presa in considerazione anche per il controllo dei nomi. Se il nome della variabile nel CSV per la tabella non è valido (caratteri non autorizzati), è possibile adattarlo o assegnare un nome di tabella diverso e lasciare il nome originale non valido.
Unità [Unit]: l'unità viene visualizzata nell'intestazione della colonna, tra parentesi quadre dopo la descrizione della variabile. Il valore può essere personalizzato, ma può anche essere vuoto.
Se nella prima finestra di dialogo in formato CSV [CSV-Format] è stata selezionata l'opzione Standard CADENAS [Cadenas standard], che consente solo testo o numeri, per ogni numero viene inserito automaticamente "Numero decimale (0,123)" (che è il valore predefinito per i numeri decimali in PSOL).
Se l'opzione Formato numerico esteso di CADENAS [Cadenas enhanced numbers] è stata selezionata nella prima finestra di dialogo in formato CSV [CSV-Format], la visualizzazione corrisponde esattamente alle specifiche differenziate del CSV.
Se si apre il campo elenco, è possibile regolare il formato in entrambi i casi, se necessario.
Stato [Status]: selezionare l'opzione desiderata dalla casella di riepilogo.
Variabile con valori fissi [Variable with fixed values] (default): ogni riga della tabella ha il proprio valore per questa variabile.
Variabile dell'intervallo di valori [Value range variable]: sintassi equivalente a quella del gestore di variabili [Variable Manager] di PARTdesigner.
Algoritmo caratteristico [Attribute algorithm]: Sintassi equivalente al gestore di variabili [Variable Manager] di PARTdesigner
![[Importante]](https://webapi.partcommunity.com/service/help/latest/pages/it/partsolutions_user/doc/images/important.png)
Importante Nel caso delle variabili di intervallo di valori e degli algoritmi caratteristici, non ogni riga ha il proprio valore, ma ogni riga contiene praticamente lo stesso algoritmo (o intervallo di valori). Tuttavia, il risultato dell'algoritmo può essere diverso in ogni riga.
Qui nel CSV, ogni riga contiene lo stesso algoritmo/intervallo di valori.
Identificazione del tipo [Identification type]: equivalente al gestore di variabili [Variable Manager] PARTdesigner.
Traduci [Translation]: Utilizzare la casella di controllo per specificare se la rispettiva variabile del progetto deve essere aggiunta o meno alle variabili da tradurre.
Nascondi [Hide]: Utilizzare la casella di controllo per specificare se la rispettiva variabile deve essere nascosta o meno nel progetto.
Assegnazione di gruppo [Variable group]: determinare facoltativamente l'assegnazione di gruppo di una variabile nel progetto.
In linea di principio, una variabile può essere contenuta in più gruppi. A tale scopo, inserire un elenco separato da virgole.
La rispettiva variabile può anche essere rimossa dai gruppi anteponendo il prefisso "!".
GRUPPE1,!GRUPPE2,GRUPPE4
Mit diesem Wert wird die Variable in den Gruppen "GRUPPE1" und "GRUPPE4" hinzugefügt und aus "GRUPPE2" entfernt.
Nota I gruppi devono esistere nel catalogo!
Poiché l'utente non può necessariamente modificare anche il nodo radice del catalogo quando modifica tramite batch (perché potrebbe non avere i diritti SVN per farlo), alla fine dell'esecuzione del batch il sistema può visualizzare quali nuovi gruppi sono stati aggiunti e devono ancora essere aggiunti al catalogo manualmente.
Posizione di memorizzazione [Save location]: equivalente al gestore di variabili [Variable Manager] di PARTdesigner.
Valore predefinito [Default value]: questa colonna specifica un valore predefinito nel caso in cui non venga trovata alcuna riga adatta nel CSV tramite l'identificatore.
Se nell'esempio precedente ci fosse un'altra riga nella tabella con il valore IDTAB 1022, questo non verrebbe trovato nel CSV (perché l'IDCSV non ha questo valore) e quindi il valore non potrebbe essere trasferito.
In tal caso, viene utilizzato il valore predefinito. Se non viene specificato alcun valore predefinito, viene utilizzato un valore predefinito interno (un piccolo numero "antiestetico") come ripiego.
Aggiungi colonne se non esistono ancora [Add columns if non existent]: Se questa opzione è attivata, le colonne variabili vengono create nella tabella se non esistono ancora.
Nell'esempio precedente, questa casella di controllo deve essere attivata perché "B" non esisteva in precedenza nella tabella.
Se questa casella di controllo non è attivata, vengono modificati solo i valori delle tabelle che già contengono questa variabile.
Crea colonne solo se sono disponibili dati per la tabella [Only create columns if there are table data available]: Questa opzione impedisce la creazione di una variabile in una tabella se non corrisponde una sola riga di identificatore.
Nell'esempio precedente, se nel CSV alla voce IDCSV non viene trovato un solo valore di IDTAB, la variabile non viene creata.
Area di dialogo "Condizione": (equivalente a condizione nelle altre modalità di esecuzione batch)
Qui si possono impostare le condizioni di base per l'esecuzione del batch. Ad esempio, che vengano elaborati solo i progetti visibili o solo quelli invisibili.
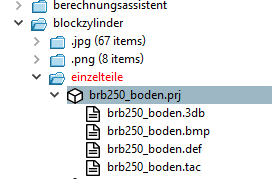
Casella di controllo Considera gerarchia [Consider hierarchy]: La struttura delle cartelle viene presa in considerazione. AD ESEMPIO: Voglio modificare solo i progetti visibili. È possibile che un progetto sia visibile, ma che una cartella sopra di esso sia nascosta.
brb250_boden.prjè se stesso visibile, ma la directoryeinzelteileè nascosta.Se è selezionata l'opzione Solo progetti visibili [Only visible projects] e la casella di controllo Includi gerarchia [Consider hierarchy] NON è selezionata, il progetto viene modificato perché è visibile. Tuttavia, se la casella di controllo Includi gerarchia [Consider hierarchy] è attivata, il progetto non viene modificato perché una directory sopra di esso è nascosta. Il sistema controlla quindi anche se qualsiasi directory sovrastante (fino al nodo radice del catalogo) è nascosta.
Il pulsante riporta alla prima finestra di dialogo, dove è possibile selezionare il file CSV.
Il pulsante avvia l'esecuzione del batch.
Il pulsante chiude la finestra di dialogo Modifica in batch [Edit in batch] senza fare nulla.
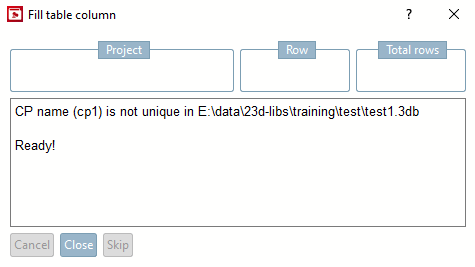
→ La finestra di dialogo Riempi colonna tabella [Fill table column] mostra lo stato di avanzamento.
→ I valori mancanti sono stati letti di conseguenza.
![Creare una tabella CSV [Create CSV table]](https://webapi.partcommunity.com/service/help/latest/pages/it/partsolutions_user/doc/resources/img/img_780ba13a63974fd8bcfea22dacb47588.png)
![Finestra di modifica nell'esecuzione batch [Edit in batch]](https://webapi.partcommunity.com/service/help/latest/pages/it/partsolutions_user/doc/resources/img/img_e669df6529bb477fab6e8857ba70a12b.png)
![Impostazioni dipendenti dalla colonna [Column Settings]](https://webapi.partcommunity.com/service/help/latest/pages/it/partsolutions_user/doc/resources/img/img_8888879dd4ce4055b9e85d4a910e7962.png)
![Finestra di riempimento delle colonne della tabella [Fill table column]](https://webapi.partcommunity.com/service/help/latest/pages/it/partsolutions_user/doc/resources/img/img_94488eea02ac4897b0c007bd37e37607.png)
La tabella seguente mostra le voci possibili nel campo Nome variabile [Name of variable].
|
Le parole chiave sono utilizzate per la comunicazione interna dei dati tra PARTproject e PARTdataManager. È possibile visualizzare le parole chiave esistenti aprendo il rispettivo file di progetto (nella directory "23d-libs") con un editor di testo. Le parole chiave sono elencate a sinistra del segno di uguale (qui: TYPE, PROJECT, SHORTNAME, ecc.). Le parole chiave possono anche essere utilizzate - e questo è importante nel contesto della funzione Modifica nell'esecuzione batch [Edit in batch] - per inserire nomi di variabili, a cui a loro volta possono essere assegnati valori fissi o valori di altre variabili. |
|
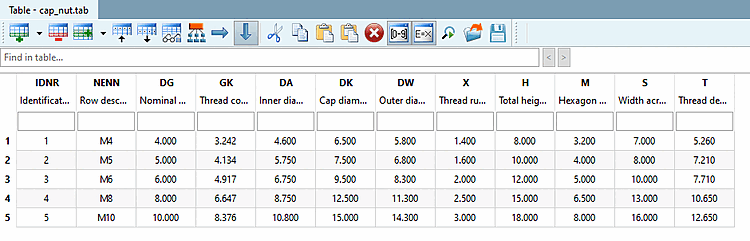
Questo verrà spiegato con l'esempio della parola chiave del campo di descrizione della riga [Row label].
È ROWDESCRIPTION e controlla la visualizzazione della colonna corrispondente nella tabella PARTdataManager. Attualmente la colonna contiene valori secondo "$NENN." (vedere il file di progetto).
Per assegnare nuovi valori a questa colonna, procedere come segue: |
| ||||
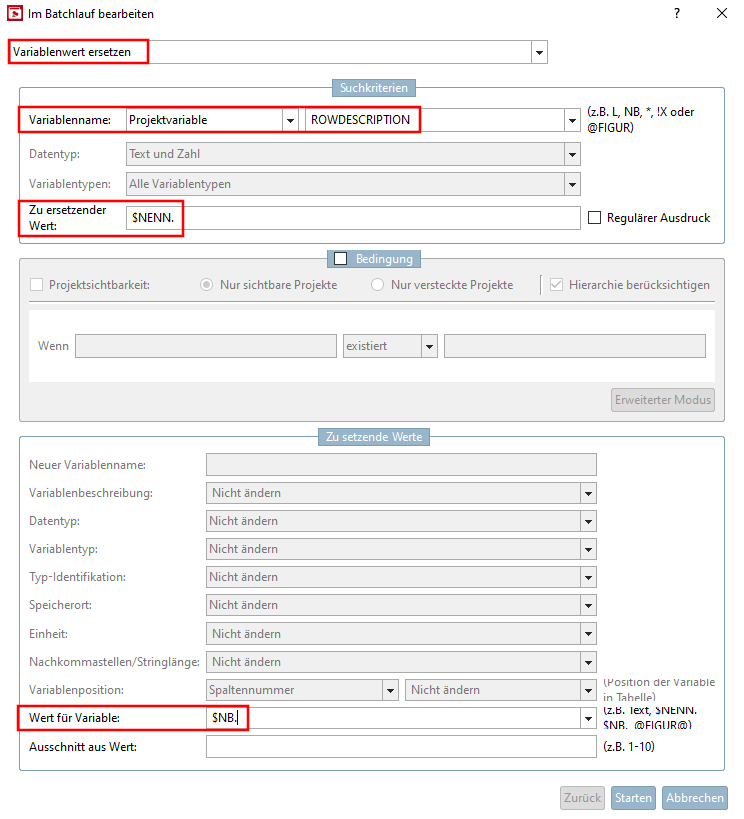
Selezionare l'opzione Sostituisci valore variabile [Replace variable value].
In Criteri di ricerca [Search criteria] - > Nome variabile [Name of variable] nella prima casella di riepilogo selezionare Variabile di progetto [Project variable] e nella seconda casella di riepilogo l'opzione
ROWDESCRIPTION.In Criteri di ricerca [Search criteria] immettere Valore per sostituire [Value to replace]
$NENN..In Valori da impostare [Values to set], immettere Valore per la variabile [Value for variable]
$NB.Uno.
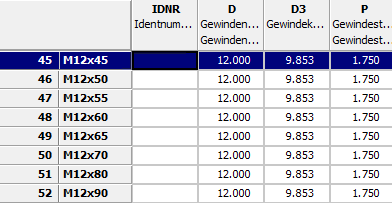
-> Il PARTdataManager contiene ora la nuova descrizione della linea NB invece di NENN.
Soprattutto nei progetti con molti 3db o punti di connessione ripetutamente richiesti, alcuni schizzi vengono utilizzati più volte e la loro copia richiede molto tempo. La copia degli schizzi tramite l'esecuzione in batch è molto più semplice e fa risparmiare tempo.
Con la funzione Modifica nell'esecuzione batch [Edit in batch], l'opzione Inserisci layer/sketch [Add plane/sketch], un layer selezionato o uno sketch selezionato viene aggiunto in tutti i progetti e in tutti i 3db.
Il nuovo schizzo viene aggiunto alla cronologia 3D [3D History] con un numero consecutivo.
Inserire uno schizzo di esempio
Salvare lo schizzo da copiare (file *.hsk) in una posizione qualsiasi.
Aprire il comando del menu contestuale Automazione [Automation] -> Modifica progetto in batch [Edit project in batch mode] tramite lo stesso progetto (per copiare tutti i 3db presenti), un altro progetto o una directory.
-> Si apre la finestra di dialogo Modifica nell'esecuzione batch [Edit in batch].
Selezionare l'opzione Inserisci layer/schizzo [Add plane/sketch] nel campo dell'elenco superiore.
Selezionare lo schizzo [Select sketch]: fare clic sul pulsante e inserire il percorso del file di schizzo.
Piano di riferimento [Reference plane]: inserire il nome del piano di riferimento su cui inserire lo schizzo.
Se il livello di riferimento non esiste [If reference plane does not exist]: Selezionare l'opzione Non inserire lo schizzo [Do not add sketch] o un layer specifico.
-> Lo schizzo viene inserito in tutti i progetti desiderati in tutti i 3db di ciascun progetto.
![Inserire uno schizzo [Insert sketch]](https://webapi.partcommunity.com/service/help/latest/pages/it/partsolutions_user/doc/resources/img/img_ad542b0a62154fd58abd4f8c6846a819.png)