1.4.1. Importazione con pipeline guidata con il tipo di importazione "QA semplificata". 1.4.1.3. Inserimento dei dati tramite procedura guidata |  |
| Indietro | Avanti |
Richiamare la procedura guidata. Sono disponibili diverse opzioni:
Inizialmente, fare clic sul pulsante Crea pipeline di importazione [Create Import pipeline] nella pagina di benvenuto [Welcome].
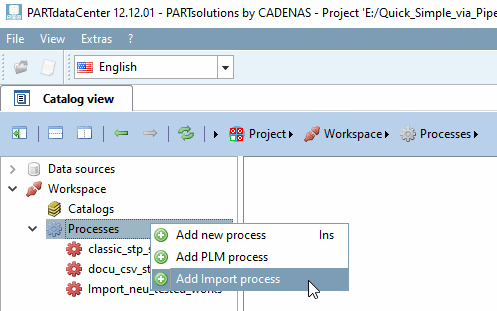
Nella pagina della scheda Vista catalogo, alla voce Processi [Processes], fare clic sul comando del menu contestuale Aggiungi processo di importazione [Add Import process].
-> Si aprirà una procedura guidata che vi guiderà passo dopo passo nel processo di inserimento.
Semplice e veloce [Quick Simple]
Per impostazione predefinita, non è necessario effettuare alcuna regolazione. Per informazioni sulle opzioni di importazione di Toleraz, consultare il sito Sezione 1.4.2, “ Impostazioni di importazione della tolleranza tramite pipeline (o tramite file di configurazione) ”.
Mappatura degli attributi [Attribute Mapping]
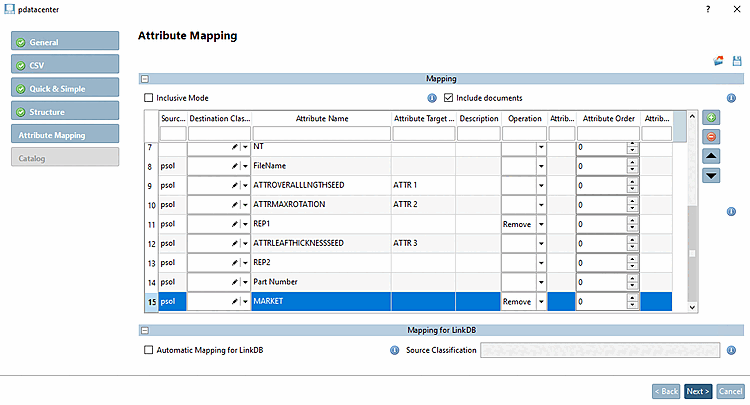
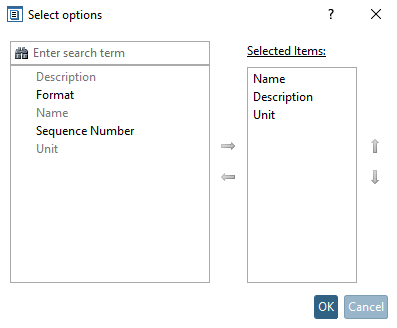
Figura 1.508. Esempio: "NomeFile", "REP1" e "MERCATO" vengono rimossi e tre attributi vengono rinominati.
Impostare gli attributi che non devono essere visualizzati nella tabella degli attributi su "Rimuovi". Se si desidera rinominare gli attributi, inserire il nome desiderato nella colonna Nome destinazione attributo [Attribute Target Name].
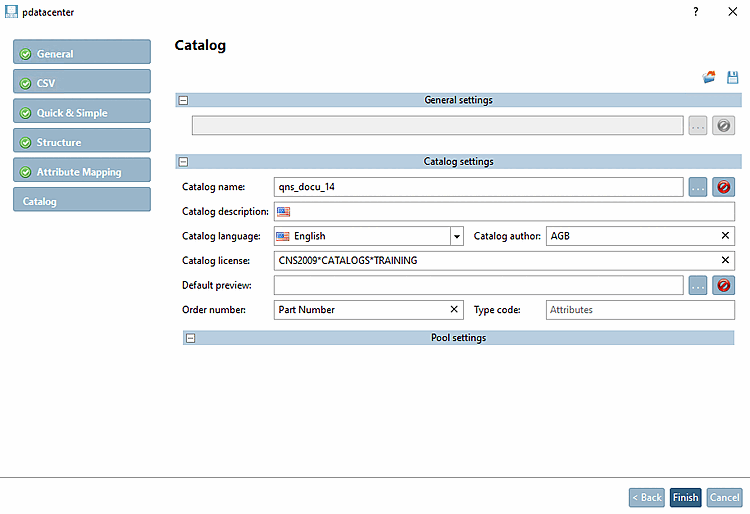
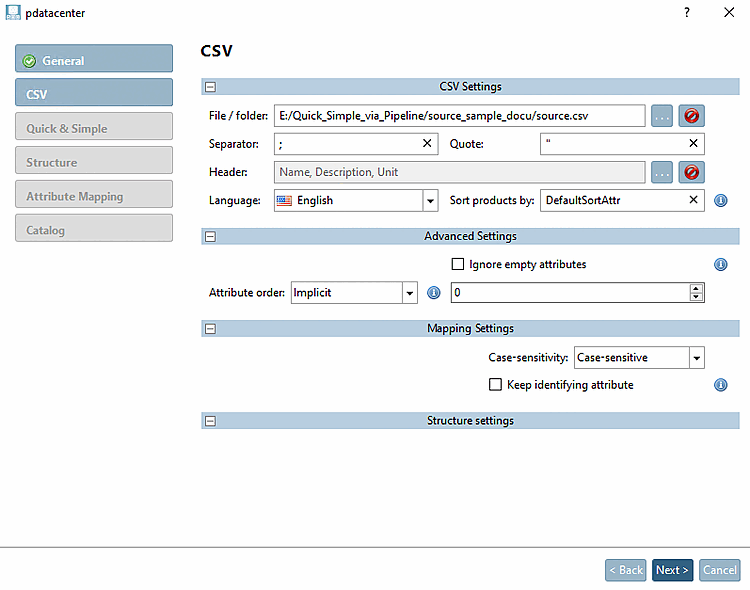
Nome catalogo [Catalog name]: inserire il nome del catalogo desiderato.
Descrizione del catalogo [Catalog description]: Selezionare la lingua desiderata.
Lingua del catalogo [Catalog language]: selezionare la lingua desiderata.
Licenza catalogo [Catalog license]: specificare una licenza (CNS2009*CATALOGS*YOURCATALOG)
Numero d'ordine [Order number]: inserire il nome della colonna per il numero d'ordine.
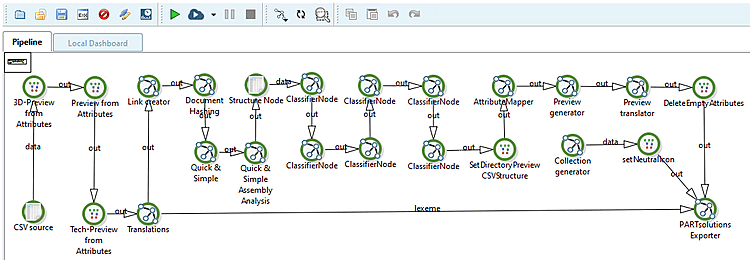
-> La pipeline viene creata automaticamente e visualizzata nella pagina della scheda Pipeline.
-> La pipeline viene eseguita.
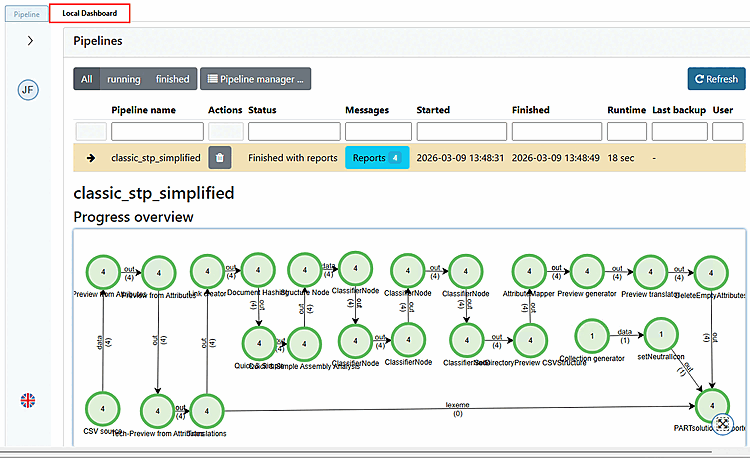
-> La visualizzazione passa alla pagina della scheda Cruscotto locale.
![Generale [General]](https://webapi.partcommunity.com/service/help/latest/pages/it/partwarehouse/doc/resources/img/img_f8adb929109b43b9b22a699362d1b17d.png)

![Semplice e veloce [Quick Simple]](https://webapi.partcommunity.com/service/help/latest/pages/it/partwarehouse/doc/resources/img/img_dddfa6f22d88488dac24295f1c2f3317.png)
![Struttura [Structure]](https://webapi.partcommunity.com/service/help/latest/pages/it/partwarehouse/doc/resources/img/img_d790238e2da54dd1a94cd3c10d8c67ca.png)
![[Nota]](https://webapi.partcommunity.com/service/help/latest/pages/it/partwarehouse/doc/images/note.png)