5.12.11.28. Elektroteile klassifizieren: Zusatzmodule 5.12.11.28.2.
Katalog mit PDT Informationen
anreichern
|  |
| Zurück | Weiter |
Über die Funktion Katalog mit PDT Informationen anreichern [Enrich catalog with PDT information] können Sie in Ihrem Katalog PDT-Informationen automatisiert verfügbar machen. Voraussetzung hierfür ist eine entsprechend aufbereitete Excel-Datei.
![[Hinweis]](https://webapi.partcommunity.com/service/help/latest/pages/de/installation/doc/images/note.png)
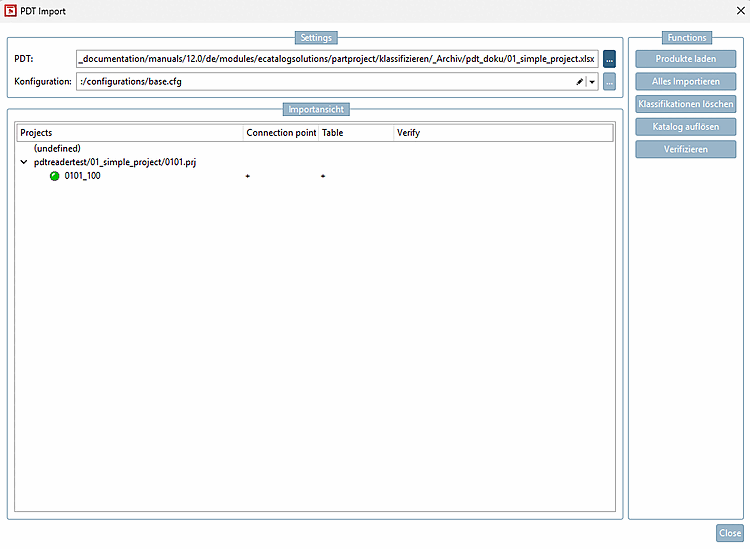
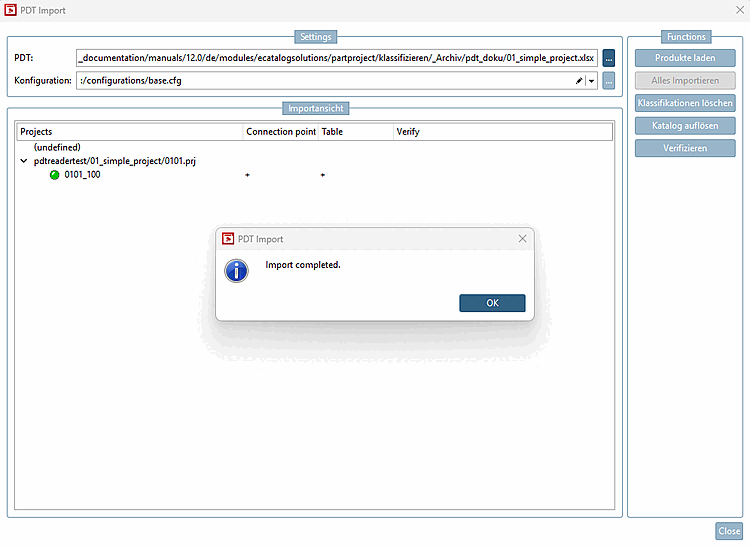
Rufen Sie unter Automatisierung [Automation] -> Katalog mit PDT Informationen anreichern [Enrich catalog with PDT information] den Dialog PDT Import auf.
![Automatisierung [Automation] -> Katalog mit PDT Informationen anreichern [Enrich catalog with PDT information]](https://webapi.partcommunity.com/service/help/latest/pages/de/installation/doc/resources/img/img_4f45c5207a6c47b88548e966eaeda9ed.png)
Automatisierung [Automation] -> Katalog mit PDT Informationen anreichern [Enrich catalog with PDT information]
-> Der Dialog PDT Import wird geöffnet.
PDT: Browsen Sie via zur gewünschten Excel-Datei bzw. Template.
Konfiguration: Wählen Sie im Listenfeld die Option
:/configurations/base.cfg.: Der Punkt ist gegenüber V12.9 entfallen, da das Zubehör über den relativen Pfad und nicht die POOL Id geschrieben wird.
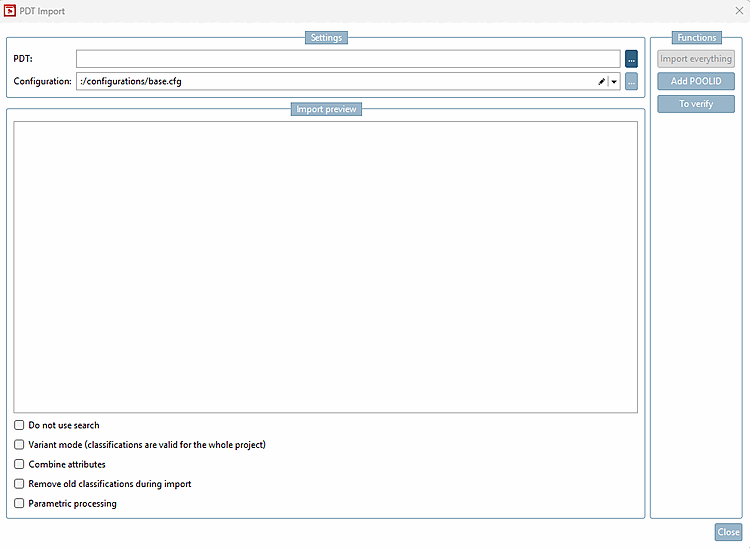
Die Auswahlkästchen unten sind gegenüber V12.9 entfallen:
Keine Suche verwenden [Do not use search] wird über den neuen Button ersetzt. So lange die Bestellnummer klassifiziert ist und es keine Varianten gibt, wird dieser nicht benötigt. Bei gelben Feldern (Wertebereichen) kann über die Funktion eine Auflösung der Varianten gestartet werden. Bestellnummern der Varianten landen in einem Cache (
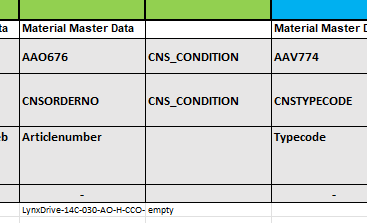
$CADENAS_USER/pdt_import/cache.json), welcher dann zur Identifizierung der korrekten Zeilen verwendet wird. Solange sich der Katalog nicht ändert, ist dies nur einmal nötig.wird über die PDT-Datei und eine CNS_CONDITION Spalte abgebildet. Sollen Klassifikationen für die ganze Projektdatei gelten ("ganz" meint für alle Werte der Wertebereichsvariablen), muss eine CNS_CONDITION mit dem Wert „empty“ gesetzt werden (in allen relevanten Tabellen möglich).
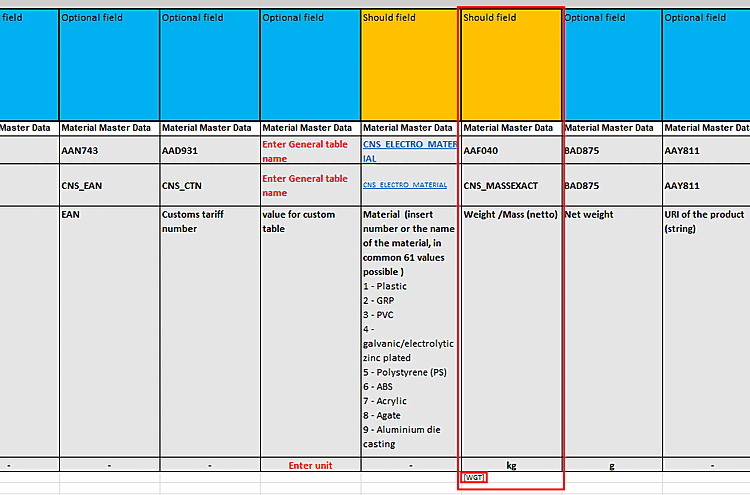
Attribute kombinieren [Combine attributes] entfällt komplett. Möchte man Felder mit Algorithmen (im Beispiel unten ist es doch kein Algorithmus, oder?), ist der empfohlene Weg, diese per Hand in die Tabelle einzupflegen und per eckige Klammern im PDT den Importer anzuweisen, auf die entsprechende Spalte zu verweisen [SPALTENNAME] -> Klassifikation verweist auf die Tabellenspalte SPALTENNAME.
Alte Klassifikationen beim Import entfernen [Remove old classifications during import]: Dies kann nach dem Laden der Produkte über den neuen Button abgebildet werden. Es werden alle Klassifikationen gelöscht, die einen Instanznamen besitzen, der mit "PDT_" beginnt.
Parametrisch verarbeiten [Parametric processing]: Entfällt und wird über die CNS_CONDITION Spalte der Excel Tabelle Connection Point Information gesteuert.
Sonstige Änderungen gegenüber V12.9:
Die Debuginformationen werden nach jedem Import unter
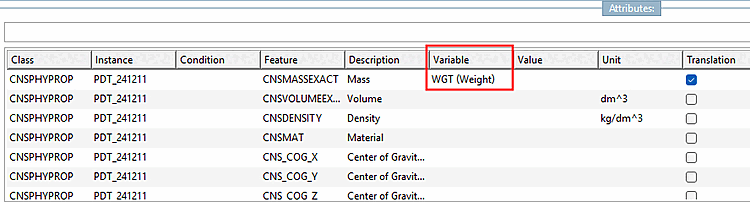
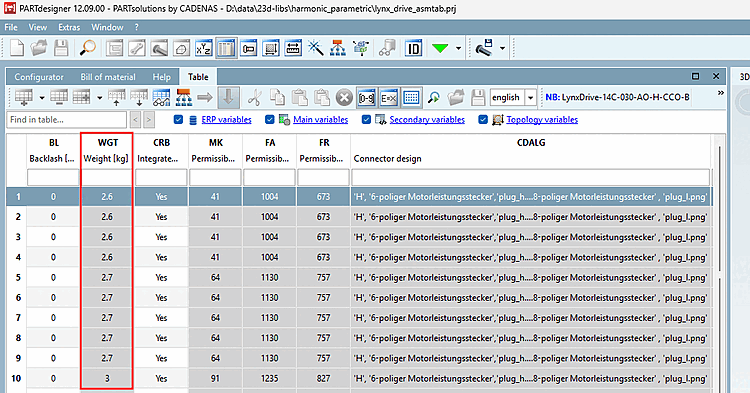
$CADENAS_USER/pdt_importgeladen.Neben der ECLASS Property Zeile wird jetzt auch die Variable name Zeile verarbeitet. Während erstere eine eindeutige Id sein sollte (bei doppeltem Auftreten wird die erste als Deutsche und die zweite als Englische Übersetzung eines Feldes angesehen), sollte die zweite einen Attributnamen enthalten, damit diese direkt auf ein Attribut einer Klasse gemapped werden kann. Das Mapping kann in der Konfigurationsdatei übersteuert werden. Letztendlich wäre es aber optimal, so viel korrektes Mapping wie möglich im PDT-Template zu haben.
Wenn 2 Baugruppen sich die gleichen Subparts teilen, werden bereits klassifizierte Anfügepunkte erkannt und mit den neuen Werten des aktuellen Imports aktualisiert. Sollen diese unterschiedliche Werte haben, müssen Baugruppenanfügepunkte verwendet werden, da unterschiedliche Werte für Punkte in diesem Fall nur möglich wären, wenn man über die CNS_CONDITION diese für ihre jeweilige Baugruppe unterscheiden könnte.
Zur Durchführung eines Imports müssen keine bestimmten Tabellen vorhanden sein. Es kann z.B. ein Import gemacht werden, der nur CP oder nur Zubehör importiert.
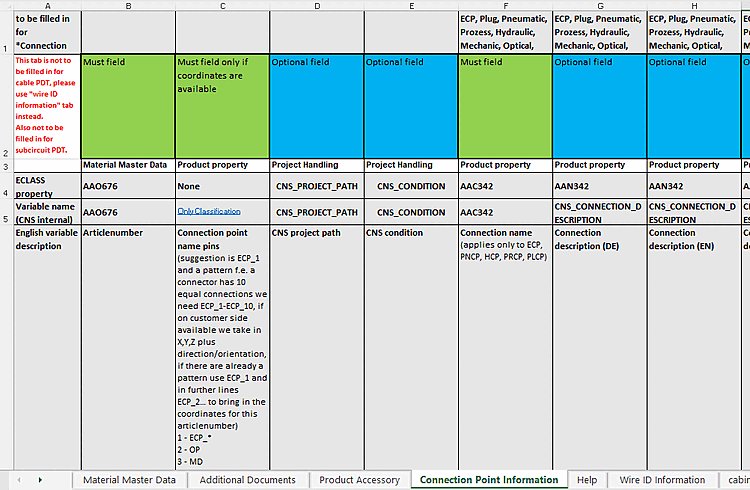
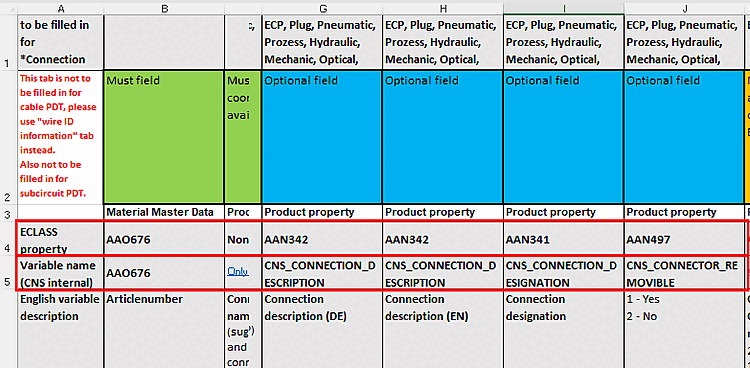
Bei Baugruppen werden Merkmale von Klassen, die keine Anfügepunkte betreffen, in das Baugruppenprojekt geschrieben (z.B. "CNSELEK"), Merkmale von Anfügepunkten ("CNS_CP") in das erste Subpart, das einen Anfügepunkt mit dem entsprechenden Namen besitzt.