- 5.8.2.1.20.1.1. Variable hinzufügen / Variablenwert ändern
- 5.8.2.1.20.1.2. Variablenwert ändern
- 5.8.2.1.20.1.3. Variablenwert ersetzen
- 5.8.2.1.20.1.4. Variablen löschen
- 5.8.2.1.20.1.5. Variable umbenennen
- 5.8.2.1.20.1.6. Variable aus CSV hinzufügen/ aus CSV Werte übernehmen
- 5.8.2.1.20.1.7. Eingabemöglichkeiten im Feld "Variablenname"
- 5.8.2.1.20.1.8. Verwendung von Schlüsselwörtern
- 5.8.2.1.20.1.9. Ebene/Sketch einfügen
Die Sachmerkmalstabellen, die den einzelnen Teilen/Projekten eines Kataloges zugeordnet sind, können per Batchlauf (Stapelverarbeitung) modifiziert werden.
Es gibt verschiedene Möglichkeiten, die Tabellenvariablen zu bearbeiten. Die Auswahl des gewünschten Modus erfolgt im obersten Listenfeld:
Je nach gewählter Option sind die entsprechenden Eingabefelder in den Abschnitten Suchkriterien [Search criteria] und Zu setzende Werte [Values to set] aktiv.
![Im Batchlauf bearbeiten [Edit in batch]](https://webapi.partcommunity.com/service/help/latest/pages/de/installation/doc/resources/img/img_2bbc312443b4475d9df7fbc4c98f260f.png)
Nehmen Sie die entsprechenden Einstellungen vor und klicken Sie auf .
In den folgenden Abschnitten finden Sie Erläuterungen zu den einzelnen Optionen.
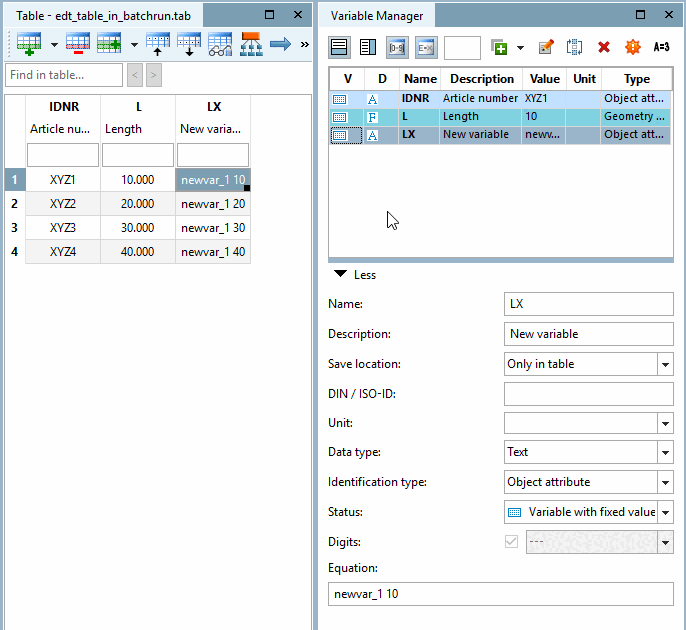
Die Funktion ermöglicht das Hinzufügen einer neuen Variablen und gleichzeitig das Setzen des Variablenwertes, aber auch das Setzen von Eigenschaften wie beispielsweise der Spaltenposition innerhalb der Tabelle.
Wählen Sie die Option Variable hinzufügen / Variablenwert ändern [Add variable / change variable value].
Einstellungen im Abschnitt Suchkriterien [Search criteria]:
Geben Sie unter Variablenname [Name of variable] → Tabellen-/Geometrievariable [Table/geometry variables] den Variablennamen ein.
Belassen Sie die Voreinstellung unter Datentyp [Data type] auf Text und Zahl [Text and number].
Belassen Sie die Voreinstellung unter Variablentypen [Variable types] auf Alle Variablentypen [All variable types].
Einstellungen im Abschnitt Zu setzende Werte [Values to set]:
Variablenbeschreibung [Variable description] (optional)
Typ-Identifikation [Identification type]: (siehe auch Abschnitt 7.8.14, „ Typ-Identifikation “)
Speicherort [Save location]: (siehe auch Abschnitt 7.8.11, „ Speicherort: Nur in Geometrie | Nur in Tabelle | In Geometrie und Tabelle “)
Variablenposition [Variable position]:
Mit der Variablenposition [Variable position] „2“ beispielsweise setzen Sie die neue Variable an die 2. Stelle innerhalb der Tabelle.
Wert für Variable [Value for variable]: Als Wert kann sowohl ein fixer Wert als auch eine Variable eingesetzt werden.
Ausschnitt aus Wert [Cutout from value]:
Wollen Sie nicht den ganzen Ausdruck „$NB.“ als Variablenwert einsetzen, sondern nur einen Teilstring, begrenzen Sie unter Ausschnitt aus Wert [Cutout from value] z.B. auf die Zeichen „1-5“.
![Dialogfenster Im Batchlauf bearbeiten [Edit in batch]](https://webapi.partcommunity.com/service/help/latest/pages/de/installation/doc/resources/img/img_6b9b5addc5ba4f489a273e9417d1c4bb.png)
![Beispiel einer Variablenbeschreibung [Variable description]](https://webapi.partcommunity.com/service/help/latest/pages/de/installation/doc/resources/img/img_4078932b1c3c4b959cadb4b9c3780f0e.png)
→ Die neue Variable ist als 3. Spalte in die Tabelle integriert. Die Beschreibung ist unterhalb des Variablennamens angezeigt. Als Variablenwert wurde die Normbezeichnung eingetragen.
![[Hinweis]](https://webapi.partcommunity.com/service/help/latest/pages/de/installation/doc/images/note.png) | Hinweis |
|---|---|
Funktionell besteht kein Unterschied, ob eine neue Variable mit einem gewünschten Wert hinzugefügt wird oder ob der Wert einer bestehenden Variable geändert wird. Daher sind die Einstellungsoptionen der Funktionen Variable hinzufügen / Variablenwert ändern [Add variable / change variable value] und Variablenwert ändern [Change value of variable] identisch. Vergleiche Abschnitt 5.8.2.1.20.1.1, „ Variable hinzufügen / Variablenwert ändern “. | |
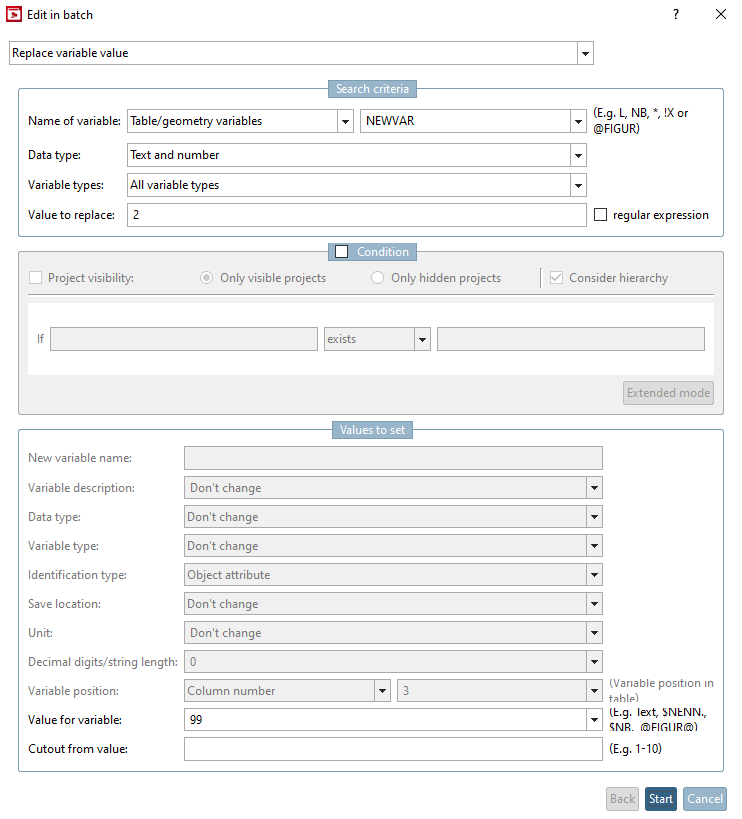
Die Option Variablenwert ersetzen [Replace variable value] ermöglicht die Angabe eines bestimmten Wertes (Zu ersetzender Wert [Value to replace]) als Suchkriterium.
Wählen Sie die Option Variablenwert ersetzen [Replace variable value].
Bestimmen Sie unter Variablenname [Name of variable] im ersten Listenfeld die gewünschte Option und im zweiten Listenfeld die betreffende Variable (hier beispielhaft NEWVAR).
Geben Sie unter Zu ersetzender Wert [Value to replace] den aktuellen Variablenwert an (hier „2“). (Es können auch reguläre Ausdrücke verwendet werden, wenn das Auswahlkästchen Regulärer Ausdruck [Regular expression] aktiviert wird.)
Geben Sie unter Zu setzende Werte [Values to set] -> Wert für Variable [Value for variable] den neuen Variablenwert (hier „99“) ein.
Rufen Sie die Tabellendatei(en) der betreffenden Projekte auf.
→ Der/die geänderte(n) Spaltenwert(e) ist/sind übernommen.
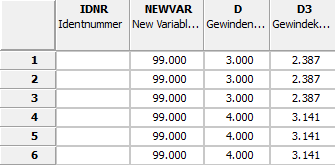
Selektieren Sie im Dialogfenster Im Batchlauf bearbeiten [Edit in batch] die Option Variablen löschen [Delete variables].
Variablenname [Name of variable]:
Wählen Sie im ersten Listenfeld aus Tabellen-/Geometrievariable [Table/geometry variables], Projektvariable [Project variable] oder Sonstiges [Other] die gewünschte Option.
Wählen Sie im zweiten Listenfeld die gewünschte Variable. Sie können auch mit freier Eingabe kommasepariert mehrere Variablen eingeben.
Belassen Sie die Voreinstellungen in den Feldern Datentyp [Data type] und Variablentypen [Variable types].
Alternativ können Sie auch den Platzhalter "*" für alle Variablen setzen. In diesem Fall filtern Sie dann über die Felder Datentyp [Data type] und Variablentypen [Variable types].
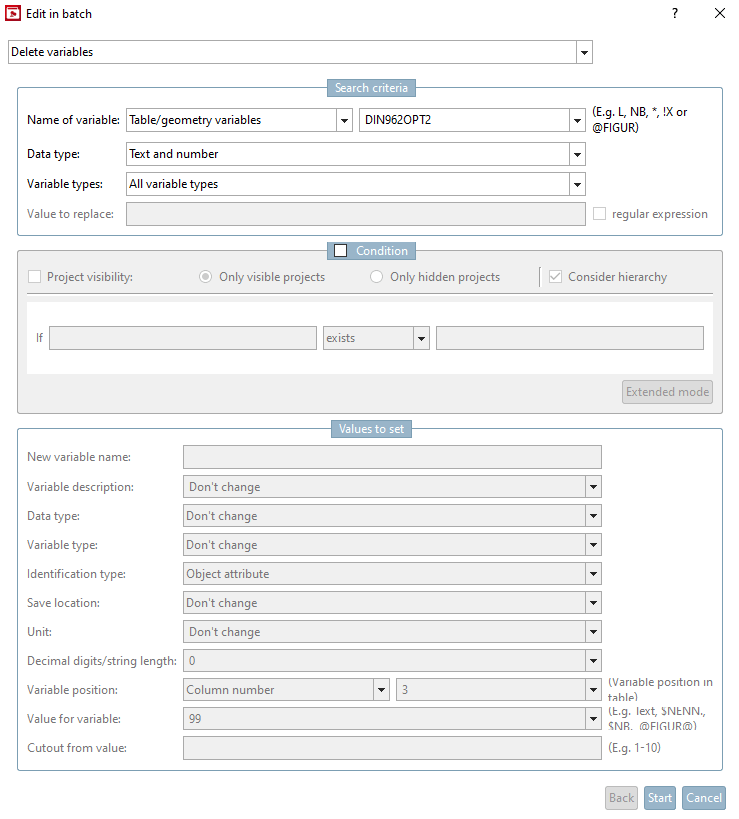
Selektieren Sie im Dialogfenster Im Batchlauf bearbeiten [Edit in batch] die Option Variable umbenennen [Rename variable]. Aktivieren Sie gegebenenfalls auch das Auswahlkästchen Verweise in Assemblies anpassen [Adapt links in assemblies].
Tragen Sie unter Suchkriterien [Search criteria] -> Variablenname [Name of variable] den zu ändernden Variablennamen ein.
In der Regel belassen Sie die Voreinstellung unter Datentyp [Data type] und Variablentypen [Variable types] (Text und Zahl [Text and number], Alle Variablentypen [All variable types]).
Tragen Sie unter Zu setzende Werte [Values to set] -> Neuer Variablenname [New variable name] den neuen Variablennamen ein.
Tragen Sie optional unter Zu setzende Werte [Values to set] -> Variablenbeschreibung [Variable description] die neue Variablenbeschreibung ein.
Sie können Tabellenwerte aus einer CSV-Datei übernehmen und/oder Variablen aus einer CSV-Datei hinzufügen. Im Folgenden wird der Ablauf anhand eines Beispiels verdeutlicht.
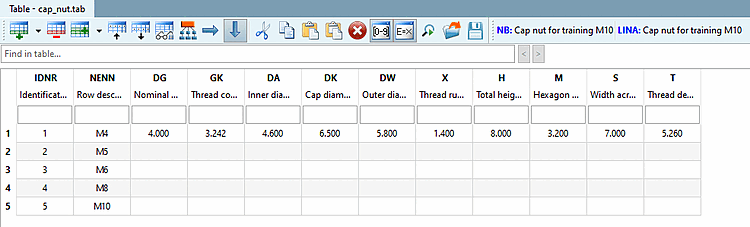
Für eine Zeile sind die Variablenwerte vollständig. Die übrigen Zeilen sollen aus der CSV-Datei befüllt werden.
Außerdem besteht die Möglichkeit weitere fehlende Angaben wie Einheit [Unit] zuzufügen oder nicht zutreffende Angaben wie z.B. Speicherort [Save location] zu korrigieren.
Stellen Sie die gewünschten Werte in Form einer CSV-Datei zur Verfügung:
Benötigte Struktur der CSV-Datei bei Auswahl Cadenas standard [Cadenas standard]:
In der Datentyp [Data type] Zeile verwenden Sie "T" für Text und Z für Zahl.
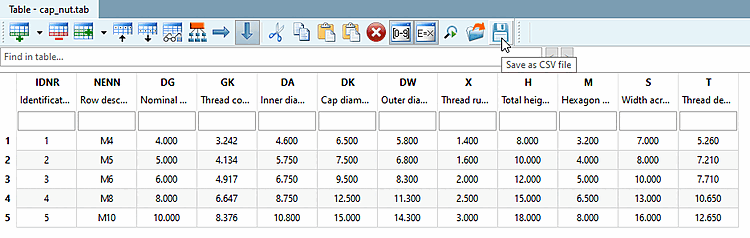
IDNR;NENN;DG;GK;DA;DK;DW;X;H;M;S;T Identifikationsnummer;Zeilenbeschreibung;Gewindenenndurchmesser;...;.....;... ;;mm;mm;mm;mm;mm;mm;mm;mm;mm;mm T;T;Z;Z;Z;Z;Z;Z;Z;Z;Z;Z 1;M4;4;3.242;4.6;6.5;5.8;1.4;8;3.2;7;5.26 2;M5;5;4.134;5.75;7.5;6.8;1.6;10;4;8;7.21 3;M6;6;4.917;6.75;9.5;8.3;2;12;5;10;7.71 4;M8;8;6.647;8.75;12.5;11.3;2.5;15;6.5;13;10.65 5;M10;10;8.376;10.8;15;14.3;3;18;8;16;12.65
Eine solche Struktur der CSV-Datei erhalten Sie z.B. mittels Kontextmenübefehl im PARTproject Katalogindex → Ausgabe [Output] → CSV-Tabelle erzeugen [Create CSV table].
Benötigte Struktur der CSV-Datei bei Auswahl Cadenas erweitertes Zahlenformat [Cadenas enhanced numbers]:
In der Datentyp [Data type] Zeile verwenden Sie "A10" für Text, "I1" für Ganzzahl und "F5.1" bis F5.5" für Dezimalzahlen.
"IDNR";"NENN";"DG";"GK";"DA";"DK";"DW";"X";"H";"M";"S";"T" "Identifikationsnummer";"Zeilenbeschreibung";"Gewindenenndurchmesser";"...";.....;"..." "";"";"";"";"";"";"";"";"";"";"";"" "A10";"A10";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3" "1";"M4";"4";"3.242";"4.6";"6.5";"5.8";"1.4";"8";"3.2";"7";"5.26" "2";"M5";"5";"4.134";"5.75";"7.5";"6.8";"1.6";"10";"4";"8";"7.21" "3";"M6";"6";"4.917";"6.75";"9.5";"8.3";"2";"12";"5";"10";"7.71" "4";"M8";"8";"6.647";"8.75";"12.5";"11.3";"2.5";"15";"6.5";"13";"10.65" "5";"M10";"10";"8.376";"10.8";"15";"14.3";"3";"18";"8";"16";"12.65"
Eine solche Struktur der CSV-Datei erhalten Sie z.B. im PARTdesigner → Tabelle → Als CSV-Datei speichern.
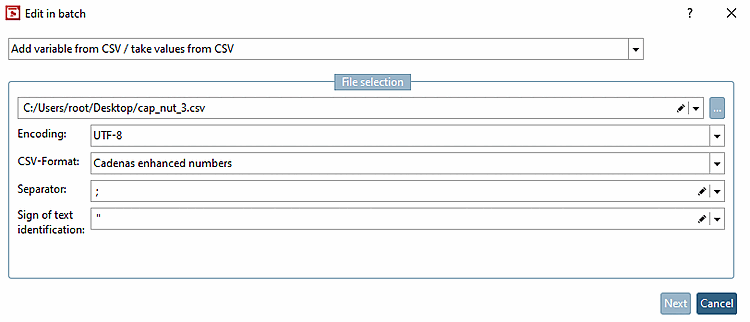
Wählen Sie die Option Variable aus CSV hinzufügen/ aus CSV Werte übernehmen [Add variable from CSV / take values from CSV].
Dialogbereich "Dateiauswahl [File selection]":
Tragen Sie eine CSV manuell ein oder wählen Sie über die Durchsuchen Schaltfläche eine oder auch mehrere (Strg-Taste) CSV-Dateien aus. Wenn mehrere ausgewählt wurden, werden diese mit dem Pipe-Symbol separiert.
Gemeint ist die Textcodierung, i.d.R. UTF-8. So kann in jedem Fall sichergestellt werden, dass z.B. Umlaute korrekt behandelt werden. Mit der Standardeinstellung UTF-8 sollte dies in den meisten Fällen gewährleistet sein.
Sollte eine andere Kodierung nötig sein, kann dies hier eingestellt werden (z.B. wenn sehr alte CSV-Dateien gelesen werden sollen, die ANSI kodiert sind und irgendwelche Sonderzeichen enthalten).
In der CSV-Datei kann nur "T" für Text und "Z" für Zahl angegeben werden.
Variable1;Variable2;Variable3;... Variable description 1;Variable description 2;Variable description 3;... ;;Einheit;Einheit;... T;T;Z;Z;Z;Z;Z;Z;Z;Z;Z;Z Daten Daten ...Für jede Zahl wird automatisch "Dezimalzahl (0.123)" eingetragen, da dies in PSOL der Default für Dezimalzahlen ist. Wenn Sie im Dialog das Listenfeld aufklappen, können Sie aber folgende Anpassungen vornehmen:
Wird z.B. verwendet für einen Export, wenn man in PARTproject auf einem Projekt den Kontextmenübefehl Ausgabe [Output] → CSV-Tabelle erzeugen [Create CSV table] ausführt.
Cadenas erweitertes Zahlenformat [Cadenas enhanced numbers]
4. Zeile: Datentyp, aber hier mit PSOL VIDA Darstellung
Variable1;Variable2;Variable3;... Variable description 1;Variable description 2;Variable description 3;... ;;Einheit;Einheit;... "A10";"A10";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3";"F5.3" Daten Daten ...Alle weiteren Zeilen enthalten die Daten.
Die Datenstruktur ist also bis auf den Datentyp die gleiche wie bei Cadenas standard.
Wird z.B. verwendet im PARTdesigner, wenn man bei der Tabelle auf Als CSV-Datei speichern [Save as CSV file] klickt.
Kein bestimmtes Format [No specific format]
Dieses Format bietet keine Möglichkeit Beschreibung, Einheit oder Datentyp festzulegen. Es ist immer Text und sollte daher nur verwendet werden, wenn andere Information nicht vorhanden ist.
Automatisch erkennen [Try to detect]
Hier wird versucht eines der beiden CADENAS-Formate zu erkennen. Gelingt dies nicht, wird die Option Kein bestimmtes Format [No specific format] verwendet.
Gibt an, mit welchem Zeichen die Spalten voneinander getrennt sind in der CSV. Hintergrund: In Deutschland wird bei Dezimalzahlen ein Komma zur Nachkommastellentrennung benutzt; also könnte ein Komma nicht als Trennzeichen für Spalten genommen werden. Da verschiedene Exporter CSV mit verschiedenen Trennzeichen erstellen, kann dies hier entsprechend eingestellt werden, um es richtig einzulesen.
Texterkennungszeichen [Sign of text identification] ist ähnlich.
Nun wird die CSV eingelesen und man wird auf die nächste Dialogseite weitergeleitet, in der nun die Informationen die aus der CSV geladen wurden, nochmal angepasst und erweitert werden können.
Dialogbereich "Spaltenabhängige Einstellungen [Column Settings]":
Passen Sie diese gegebenenfalls entsprechend an.
Aktivieren Sie bei allen Variablen, für die Sie Änderungen vornehmen möchten, das Auswahlkästchen.
Identifizierende Spalte [Identifying Column] / Variablenname im Katalog [Variable name in the catalog]:
Bestimmen Sie diejenige Variable, über welche Sie die Zuordnung zwischen CSV-Datei und Katalog herstellen möchten. Im Listenfeld von Identifizierende Spalte [Identifying Column] werden alle Spalten (Variablen) der CSV-Datei angezeigt.
(In obiger beispielhafter Abbildung wird das Mapping über die Variable "IDNR" hergestellt. In der Praxis wird dies meist die Variable der Identifikationsnummer sein. Bei einer eindeutigen Identifikationsnummer kann auch bei Verwendung mehrerer CSV-Dateien die Zuordnung zum richtigen Projekt problemlos hergestellt werden.)
Tragen Sie im Eingabefeld von Variablenname im Katalog [Variable name in the catalog] diejenige Variable ein, über welche Sie die Zuordnung zwischen CSV-Datei und Katalog herstellen möchten.
Anhand der Zuordnung zwischen Identifizierende Spalte [Identifying Column] und Variablenname im Katalog [Variable name in the catalog] können die Daten der richtigen Zeile zugeordnet werden.
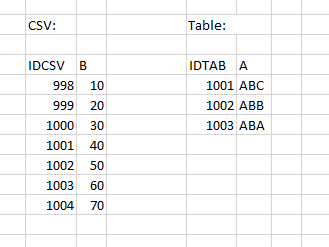
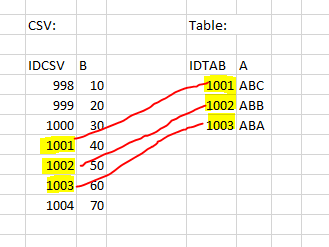
Kleines Beispiel: Die CSV hat die Spalten "IDCSV" und "B"; die Tabelle hat die Spalten "IDTAB" und "A". Es soll nun aus der CSV die Variable "B" in die Tabelle hinzugefügt werden. Die CSV hat aber viel mehr Zeilen.
Wenn Sie jetzt IDCSV als „Identifizierende Spalte [Identifying Column]“ und IDTAB als „Variablenname im Katalog [Variable name in the catalog]“ wählen, können so die richtigen 3 Werte von B zur Tabelle hinzugefügt werden, nämlich genau da, wo IDCSV und IDTAB den gleichen Wert besitzen.
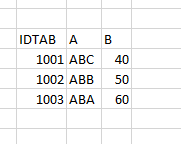
Im Ergebnis sieht die befüllte Tabelle dann so aus.
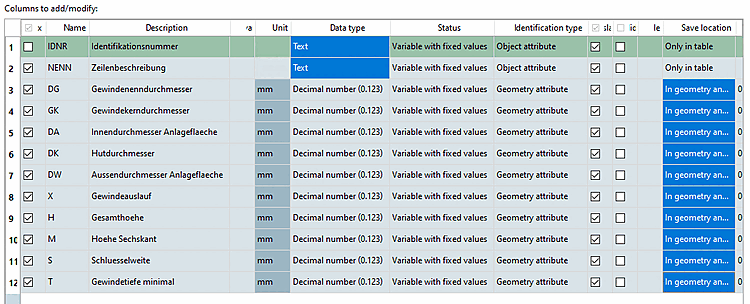
Zu verändernde/hinzuzufügende Spalten [Columns to add/modify]:
Im Folgenden ist die Bedeutung der einzelnen Tabellenspalten erklärt:
Auswahlkästchen: Aktivieren Sie bei denjenigen Variablen das Auswahlkästchen, wo Sie die Variablenwerte ändern möchten.
Mittels Auswahlkästchen im Spaltenkopf (x) können Sie alle Variablen aktivieren oder deaktivieren.
Beschreibung [Description]: Variablenbeschreibung, die in der Tabelle unter dem Variablennamen angezeigt wird.
Tabellenvariable [Table variables]: Geben Sie hier einen Namen ein, wenn die Variable aus der CSV in die Tabelle kopiert werden soll, dort aber einen anderen Namen haben soll. Wenn das Feld leer ist, wird der Name aus der CSV (Spalte „Name“) übernommen.
Die Angabe wird auch bei der Prüfung der Namen berücksichtigt. Wenn der Variablenname in der CSV für die Tabelle ungültig ist (unerlaubte Zeichen), können Sie diesen entweder anpassen, oder einen anderen Tabellennamen vergeben und den Originalnamen ungültig lassen.
Einheit [Unit]: Die Einheit wird im Spaltenkopf, in eckigen Klammern hinter der Variablenbeschreibung angezeigt. Der Wert kann angepasst werden, darf aber auch leer sein.
Wurde im ersten Dialog unter CSV-Format die Option Cadenas standard gewählt, welche nur Text oder Zahl zulässt, wird hier für jede Zahl automatisch "Dezimalzahl (0.123)" eingetragen (was in PSOL der Default für Dezimalzahlen ist).
Wurde im ersten Dialog unter CSV-Format die Option Cadenas erweitertes Zahlenformat [Cadenas enhanced numbers] gewählt, entspricht die Darstellung exakt der differenzierten Vorgabe aus der CSV.
Wenn Sie das Listenfeld öffnen, können Sie in beiden Fällen das Format gegebenenfalls anpassen.
Status: Wählen Sie im Listenfeld die gewünschte Option.
Variable mit festen Werten [Variable with fixed values] (Standard): Jede Tabellenzeile hat für diese Variable einen eigenen Wert.
Wertebereichsvariable [Value range variable]: Syntax äquivalent zu PARTdesigner Variablenmanager [Variable Manager].
Merkmalsalgorithmus [Attribute algorithm]: Syntax äquivalent zu PARTdesigner Variablenmanager [Variable Manager]
![[Wichtig]](https://webapi.partcommunity.com/service/help/latest/pages/de/installation/doc/images/important.png)
Wichtig Bei Wertebereichsvariablen und Merkmalsalgorithmen hat nicht jede Zeile einen eigenen Wert, sondern in jeder steht quasi derselbe Algorithmus (oder Wertebereich). Das Ergebnis des Algorithmus kann aber in jeder Zeile anders sein.
Hier in der CSV steht in jeder Zeile der gleiche Algorithmus/Wertebereich.
Typ-Identifikation [Identification type]: Äquivalent zu PARTdesigner Variablenmanager [Variable Manager]
Übersetzen [Translation]: Bestimmen Sie per Auswahlkästchen, ob die jeweilige Variable im Projekt zu den zu übersetzenden hinzugefügt werden soll oder nicht.
Verstecken [Hide]: Bestimmen Sie per Auswahlkästchen, ob die jeweilige Variable im Projekt versteckt sein soll oder nicht.
Gruppenzuordnung [Variable group]: Bestimmen Sie hier optional die Gruppenzugehörigkeit einer Variablen im Projekt.
Grundsätzlich kann eine Variable in mehreren Gruppen enthalten sein. Tragen Sie hierfür eine kommaseparierte Liste ein.
Mit vorangestelltem "!" kann die jeweilige Variable auch aus Gruppen entfernt werden.
GRUPPE1,!GRUPPE2,GRUPPE4
Mit diesem Wert wird die Variable in den Gruppen "GRUPPE1" und "GRUPPE4" hinzugefügt und aus "GRUPPE2" entfernt.
Hinweis Gruppen müssen im Katalog existieren!
Da der Anwender beim Bearbeiten über Batch nicht zwangsläufig auch den Katalog-Root-Knoten bearbeiten kann (weil er hierfür evtl. keine SVN-Rechte besitzt), wird am Ende des Batchlaufes gegebenenfalls angezeigt, welche Gruppen neu hinzugekommen sind und noch dem Katalog manuell hinzugefügt werden müssen.
Speicherort [Save location]: Äquivalent zu PARTdesigner Variablenmanager [Variable Manager]
Default-Wert [Default value]: Diese Spalte gibt einen Default-Wert an für den Fall, dass in der CSV keine passende Zeile über den Identifizierer gefunden wird.
Wäre im Beispiel oben in der Tabelle eine weitere Zeile mit IDTAB Wert 1022, würde diese nicht in der CSV gefunden (weil IDCSV keinen solchen Wert besitzt) und könnte somit der Wert nicht übertragen werden.
In einem solchen Fall wird dann der Default-Wert eingesetzt. Ist kein Default-Wert angegeben, wird als Fallback ein interner Default-Wert ("unschöne" kleine Zahl) genommen.
Spalten hinzufügen wenn sie noch nicht existieren [Add columns if non existent]: Wird die Option aktiviert, dann werden Variablenspalten gegebenenfalls in der Tabelle angelegt, falls sie dort noch nicht existieren.
Im Beispiel oben müsste dieses Auswahlkästchen aktiviert sein, weil "B" vorher in der Tabelle nicht existierte.
Wenn dieses Auswahlkästchen nicht aktiviert ist, dann werden nur solche Werte in Tabellen angepasst, die bereits diese Variable beinhalten.
Spalten nur anlegen, wenn Daten für die Tabelle vorhanden sind [Only create columns if there are table data available]: Diese Option vermeidet, dass eine Variable in einer Tabelle angelegt wird, wenn keine einzige Identifier-Zeile trifft.
Wenn also im obigen Beispiel kein einziger Wert von IDTAB in der CSV unter IDCSV gefunden wird, dann wird die Variable nicht angelegt.
Dialogbereich "Bedingung": (Äquivalent zu Bedingung in den anderen Batchlauf-Modi)
Hier können grundlegende Bedingungen für den Batchlauf gesetzt werden. Wie zum Beispiel, dass nur sichtbare Projekte bearbeitet werden, oder eben nur unsichtbare.
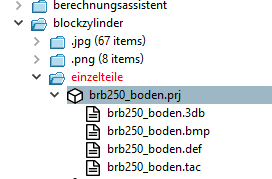
Auswahlkästchen Hierarchie berücksichtigen [Consider hierarchy]: Die Ordnerstruktur wird berücksichtigt. Z.B.: Ich möchte nur sichtbare Projekte bearbeiten. Es kann sein, dass ein Projekt selbst sichtbar ist, aber ein darüberliegendes Verzeichnis versteckt ist.
brb250_boden.prjist selbst sichtbar, aber das Verzeichniseinzelteileist versteckt.Wenn die Option Nur sichtbare Projekte [Only visible projects] gewählt ist und aber das Auswahlkästchen Hierarchie berücksichtigen [Consider hierarchy] NICHT aktiviert ist, dann wird das Projekt bearbeitet, weil es sichtbar ist. Wenn aber das Auswahlkästchen Hierarchie berücksichtigen [Consider hierarchy] aktiviert ist, dann wird das Projekt nicht bearbeitet, da ein Verzeichnis darüber versteckt ist. Es wird also dann zusätzlich geprüft, ob irgend ein Verzeichnis darüber (bis Katalog-Root-Knoten) versteckt ist.
Button führt zurück zum ersten Dialog, wo man die CSV-Datei auswählen kann.
Button beendet den Im Batchlauf bearbeiten [Edit in batch] Dialog ohne etwas zu tun.
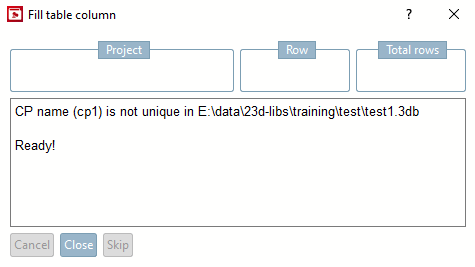
→ Der Dialog Tabellenspalte füllen [Fill table column] zeigt den Fortschritt.
→ Die fehlenden Werte wurden entsprechend eingelesen.
![CSV-Tabelle erzeugen [Create CSV table]](https://webapi.partcommunity.com/service/help/latest/pages/de/installation/doc/resources/img/img_474fe6858a054a32b89002103544238e.png)
![Fenster Im Batchlauf bearbeiten [Edit in batch]](https://webapi.partcommunity.com/service/help/latest/pages/de/installation/doc/resources/img/img_0f07634b17024fdb8fdd1d23a1ce64a3.png)
![Spaltenabhängige Einstellungen [Column Settings]](https://webapi.partcommunity.com/service/help/latest/pages/de/installation/doc/resources/img/img_14feb627b7364f46a2b535315a8050ef.png)
![Fenster Tabellenspalte füllen [Fill table column]](https://webapi.partcommunity.com/service/help/latest/pages/de/installation/doc/resources/img/img_056e3683f6904883ad5143cf32ac94a8.png)
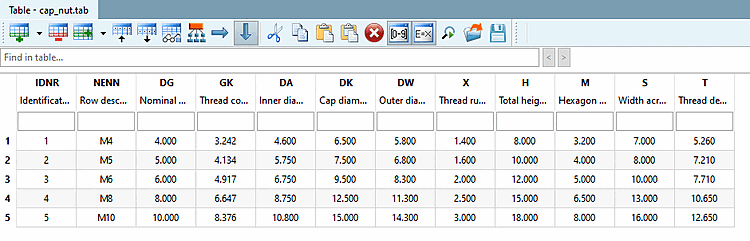
Die folgende Tabelle zeigt Eingabemöglichkeiten im Feld Variablenname [Name of variable].
|
Schlüsselwörter dienen der internen Datenkommunikation zwischen PARTproject und PARTdataManager. Sie können die vorhandenen Schlüsselwörter einsehen, indem Sie die jeweilige Projektdatei (im Verzeichnis „23d-libs“) per Texteditor öffnen. Die Schlüsselwörter sind links vom Gleichheitszeichen aufgelistet (hier: TYPE, PROJEKT, SHORTNAME, usw.). Über Schlüsselwörter lassen sich - und das ist hier im Rahmen der Funktion Im Batchlauf bearbeiten [Edit in batch] von Bedeutung - auch Variablennamen einsetzen, denen wiederum feste bzw. Werte anderer Variablen zugeordnet werden können. |
|
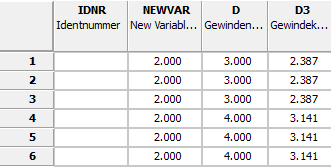
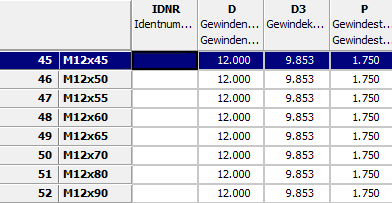
Dies soll am Beispiel des Schlüsselwortes des Feldes Zeilenbeschreibung [Row label] erläutert werden.
Es lautet ROWDESCRIPTION und steuert die Darstellung der entsprechenden Spalte in der Tabelle des PARTdataManager. Aktuell enthält die Spalte Werte gemäß „$NENN.“ (siehe Projektdatei).
Um dieser Spalte neue Werte zuzuordnen, gehen Sie folgendermaßen vor: |
| ||||
Wählen Sie die Option Variablenwert ersetzen [Replace variable value].
Wählen Sie unter Suchkriterien [Search criteria] -> Variablenname [Name of variable] im ersten Listenfeld die Option Projektvariable [Project variable] und im zweiten Listenfeld die Option
ROWDESCRIPTION.Tragen Sie unter Suchkriterien [Search criteria] bei Zu ersetzender Wert [Value to replace]
$NENN.ein.Tragen Sie unter Zu setzende Werte [Values to set] bei Wert für Variable [Value for variable]
$NB.ein.

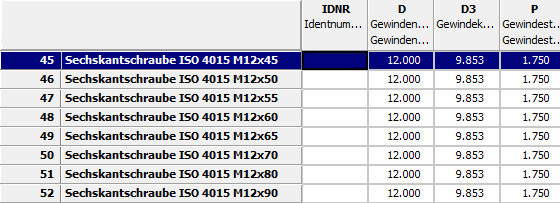
-> Im PARTdataManager steht nun anstelle von NENN die neue Zeilenbeschreibung NB.
Insbesondere bei Projekten mit vielen 3dbs oder immer wieder benötigten Anfügepunkten werden bestimmte Sketche mehrfach verwendet, wobei Kopieren sehr aufwendig ist. Viel einfacher und zeitsparender ist das Kopieren von Sketchen per Batchlauf.
Mit der Funktion Im Batchlauf bearbeiten [Edit in batch], Option Ebene/Sketch einfügen [Add plane/sketch] wird eine ausgewählte Ebene bzw. ein ausgewählter Sketch in allen Projekten und dort jeweils in allen 3dbs zugefügt.
Der neue Sketch wird mit fortlaufender Nummer in der 3D Historie [3D History] angehängt.
Speichern Sie den zu kopierenden Sketch (*.hsk-Datei) an beliebiger Stelle ab.
Öffnen Sie über demselben Projekt (um dort in alle 3dbs zu kopieren), einem anderen Projekt oder einem Verzeichnis den Kontextmenübefehl Automatisierung [Automation] -> Projekt im Batchlauf bearbeiten [Edit project in batch mode].
-> Das Dialogfenster Im Batchlauf bearbeiten [Edit in batch] wird geöffnet.
Wählen Sie im obersten Listenfeld die Option Ebene/Sketch einfügen [Add plane/sketch].
Sketch wählen [Select sketch]: Klicken Sie auf den Button und geben Sie den Pfad zur Sketchdatei an.
Referenzebene [Reference plane]: Tragen Sie den Namen der Referenzebene ein, auf welcher der Sketch eingefügt werden soll.
Wenn Referenzebene nicht existiert [If reference plane does not exist]: Wählen Sie entweder die Option Sketch nicht einfügen [Do not add sketch] oder eine bestimmte Ebene.
-> Der Sketch wird bei allen gewünschten Projekten in allen 3dbs eines jeden Projektes eingefügt.
![Sketch einfügen [Insert sketch]](https://webapi.partcommunity.com/service/help/latest/pages/de/installation/doc/resources/img/img_84b43bca97f5483d9f79c961c8263653.png)